They say that we ultimately lose information once it enters a black hole, but is this really the case? Let’s find out on today’s video. Have you ever wondered what happens to information when it falls into a black hole? Does it get destroyed forever? Does it arrive somewhere else? Does it enter a girl’s bookcase and call it for Murf? Is there a way for it to escape? Today, we’re diving into one of the biggest mysteries in physics: the black hole information paradox. But first, why should we care? Well, in case a black hole suddenly pops up in your bedroom or office table, this paradox sits at the intersection of quantum mechanics and general relativity, the two pillars of modern physics, and solving it could unlock new understandings of the universe itself. So, let’s get started. Our journey begins with looking at the basics of black holes and the paradox that has puzzled scientists for decades.
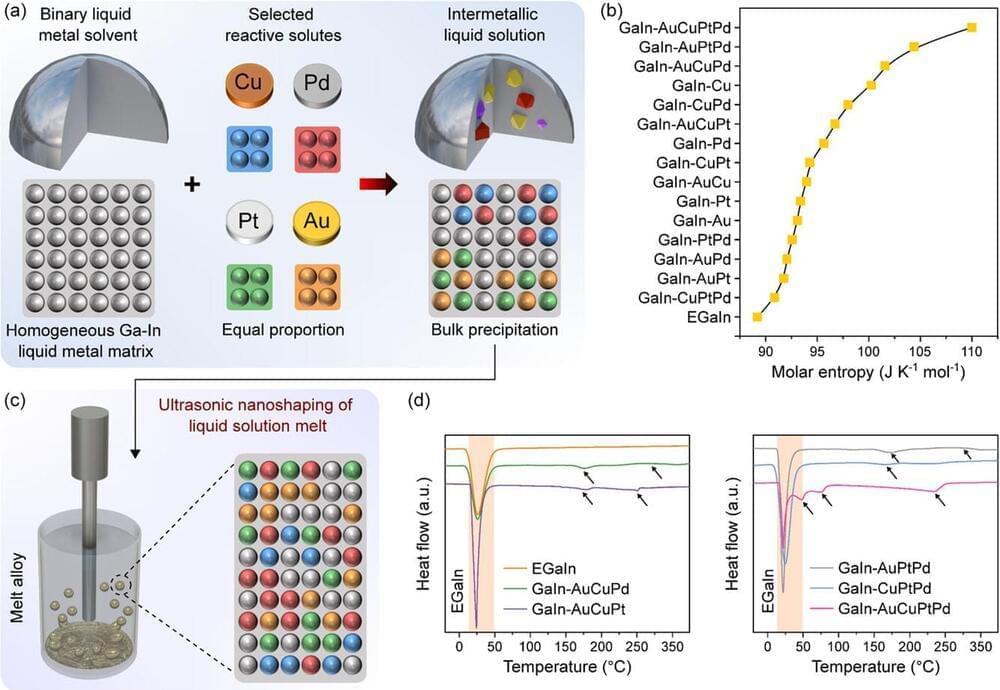
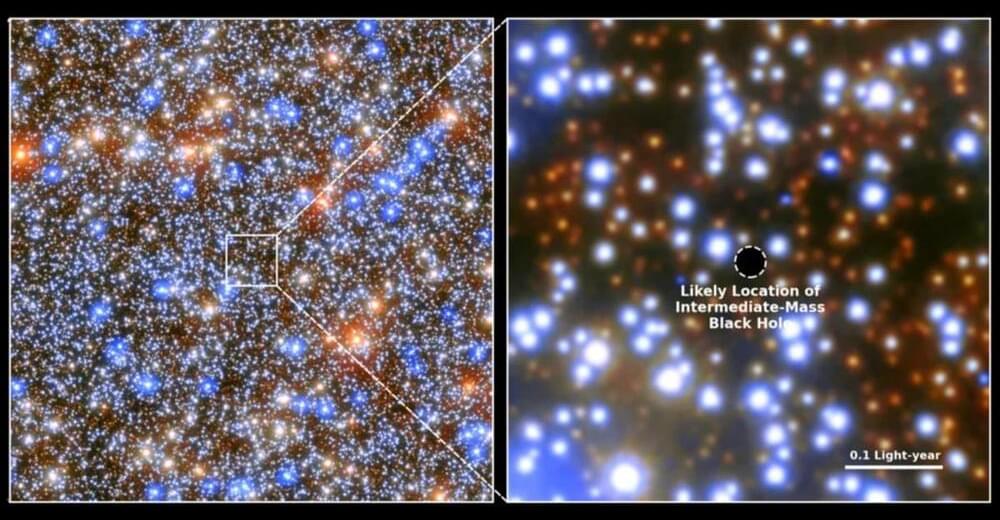
Like any good explainer, let’s begin with the basics. What exactly is a black hole? In simple terms, a black hole is a region in space where gravity is so strong that nothing, not even light, can escape from it. No Brad, it’s not a challenge; calm down. This happens when a massive star collapses under its own gravity, compressing all its mass into an incredibly small, incredibly dense point known as a singularity. Surrounding the singularity is the event horizon, the boundary beyond which nothing can return. Think of the event horizon as the ultimate point of no return. Once you cross it, you’re inevitably pulled towards the singularity, and there’s no way back. Feel like you know well about black holes? Great. Now let’s talk about Hawking radiation. In the 1970s, Stephen Hawking proposed that black holes aren’t completely black; instead, they emit a type of radiation due to quantum effects near the event horizon. This radiation, aptly named Hawking radiation, suggests that black holes can slowly lose mass and energy over time, eventually evaporating completely. But here’s where things get tricky: Hawking radiation is thermal. By that, we don’t mean that it’s smoking or anything, but that it appears to carry no information about any of the stuff that fell into the black hole. And this brings us to the heart of our mystery: the black hole information paradox. How can the information about the material that formed the black hole and fell into it be preserved if it’s seemingly lost in the radiation? With this foundation in place, I feel that we’re now ready to explore the paradox itself and the various theories proposed to resolve it.
–
DISCUSSIONS \& SOCIAL MEDIA
Commercial Purposes: [email protected].
Tik Tok: / insanecuriosity.
Reddit: / insanecuriosity.
Instagram: / insanecuriositythereal.
Twitter: / insanecurio.
Facebook: / insanecuriosity.
Linkedin: / insane-curiosity-46b928277
Our Website: https://insanecuriosity.com/
–
Credits: Ron Miller, Mark A. Garlick / MarkGarlick.com, Elon Musk/SpaceX/ Flickr.
–
00:00 Introduction.
01:07 What is a Black Hole?
01:54 Hawking Radiation.
02:46 The Black Hole Information Paradox Explained.
04:05 Entanglement Islands.
05:21 Complementarity and Quantum Hair.
06:04 Holographic Principle.
06:48 Recent Calculations and Theories.
07:56 Visualizing Complex Concepts.
09:32 Current State of Research.
11:16 Implications for Physics.
12:06 Recap and Conclusion.
–
#insanecuriosity #blackhole #astronomy