Urbanization, the process by which cities and towns expand in size and population, is rapidly advancing globally, and the percentage of people living in urban environments has increased from 33% in 1960 to 57% in 2023.
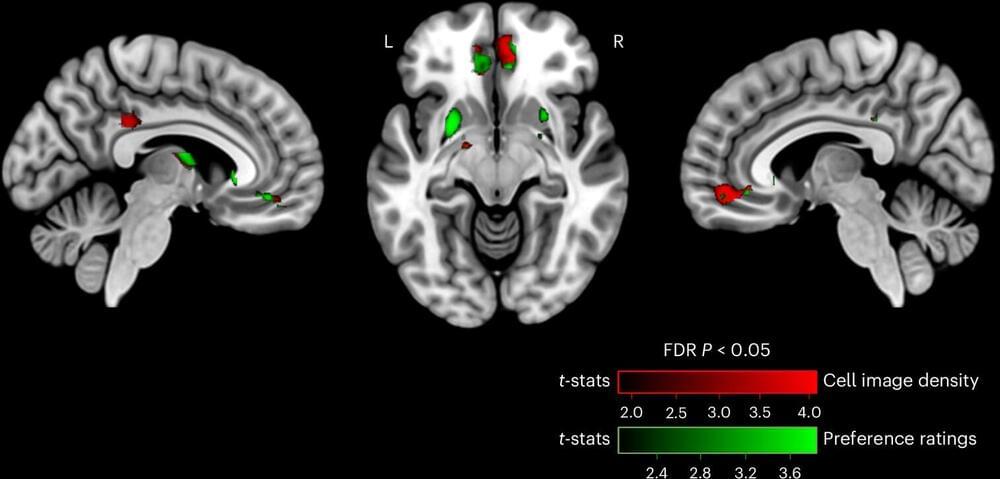
Now, researchers from Michigan State University are the first to measure brain activity to make predictions that could help inform enhanced urban planning and design that addresses the well-being of residents and visitors.
Dar Meshi, an associate professor in the Department of Advertising and Public Relations and director of the Social Media and Neuroscience Lab at MSU, led the study, which was recently published in the journal Nature Cities and included collaborators from the University of Lisbon in Portugal. Together, they found that the brain’s reward system can shape human behavior within urban environments and aid in designing cities that promote sustainable living.