Are you ready to be amazed by the incredible advancements in artificial intelligence? In 2024, AI has reached unprecedented heights, showcasing breakthroughs that are revolutionizing industries and reshaping our everyday lives. This video explores the top 9 AI breakthroughs you won’t believe are real, highlighting innovations that are both astonishing and game-changing.
From groundbreaking developments in natural language processing to cutting-edge applications in healthcare, transportation, and creative arts, we cover the most significant strides in AI technology. Discover how these breakthroughs are enhancing efficiency, improving decision-making, and creating new possibilities that were once thought to be science fiction.
But it’s not just about the technology; we’ll also discuss the implications of these advancements. As AI becomes more integrated into our lives, understanding the benefits and challenges it presents is essential. This video provides insights into how these breakthroughs could change the way we interact with machines and each other.
What are the top AI breakthroughs of 2024? How is AI changing the world? What innovations in AI should I know about? What are the latest advancements in artificial intelligence? How will AI impact our future?This video will answer all these questions. Make sure you watch till the end!
Researchers at Linköping University (LiU), Sweden, have created an artificial organic neuron that closely mimics the characteristics of biological nerve cells. This artificial neuron can stimulate natural nerves, making it a promising technology for various medical treatments in the future.
Work to develop increasingly functional artificial nervecells continues at the Laboratory for Organic Electronics, LOE. In 2022, a team of scientists led by associate professor Simone Fabiano demonstrated how an artificial organic neuron could be integrated into a living carnivorous plant to control the opening and closing of its maw. This synthetic nerve cell met two of the 20 characteristics that differentiate it from a biological nerve cell.
In their latest study, published in the journal Nature Materials, the same researchers at LiU have developed a new artificial nerve cell called conductance-based organic electrochemical neuron, or c-OECN, which closely mimics 15 out of the 20 neural features that characterize biological nerve cells, making its functioning much more similar to natural nerve cells.
A significant advancement in knowledge of the link between cognition and genetics has been made thanks to a study led by Université de Montréal graduate students Guillaume Huguet and Thomas Renne, working under the supervision of medical geneticist Sébastien Jacquemont, an associate professor of pediatrics and a researcher at the UdeM-affiliated CHU Saint-Justine.
Published in Cell Genomics, the research explored how the copy number variation, or CNV, of certain DNA segments can influence cognitive abilities.
Analyzing the CNV of nearly 260,000 people in the general population, the scientists were able to compare each individual’s CNV and cognition to define a reference model—a kind of “map” of the effects of CNV on cognition, such as the intelligence quotient and memory—and to establish links between these CNVs and achievements within the brain, as well as in other organs and tissues.
QUT researchers are part of an international group who have explored ways in which organic transistors are being developed for use as wearable health sensors.
The currently available bioelectronic devices, such as pacemakers, that can be embedded with the human body are mostly based on rigid components.
However, the next-generation devices—which are researched and developed by bioelectronic engineers, organic chemists, and materials scientists—will use soft organic materials that allow comfortable wearability as well as efficient monitoring of health.
Organic n-and p-type vertical transistors, with considerably shorter channel lengths than their planar counterparts, can be used to create complementary metal–oxide–semiconductor (CMOS)-like inverters and ring oscillators that operate in the megahertz frequency range.
A team of researchers at CHU Sainte-Justine and Université de Montréal has succeeded in using bioinformatics to develop a statistical model to assess how the gain or loss of genetic material impacts the risk of autism.
The results of this work are presented today in the American Journal of Psychiatry.
This project highlights the fact that, besides the genetic mutations formally associated with autism, there are thousands of genes in the human genome that contribute to increasing the risk and severity of autism based on genetic scores.
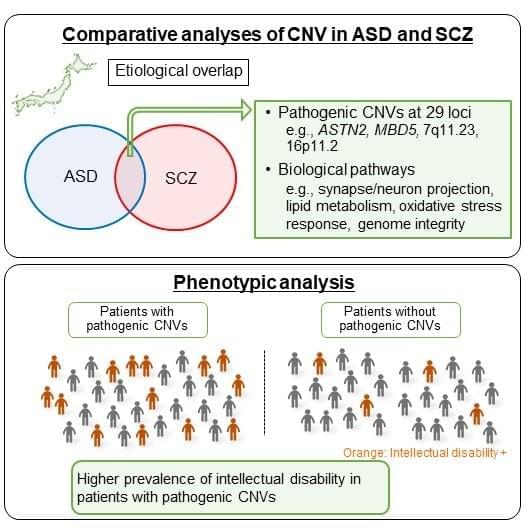
Common genetic variants may underlie autism spectrum disorder and schizophrenia across human populations, according to a study appearing September 11th in the journal Cell Reports. In line with previous studies in Caucasians, the researchers found that Japanese individuals with autism spectrum disorder and schizophrenia have overlapping copy number variations (CNVs)—inter-individual variations in the number of copies of a particular gene.
“The strength of our study is the systematic head-to-head comparison of pathogenic CNVs and biological pathways between autism spectrum disorder and schizophrenia,” says senior study author Norio Ozaki of Nagoya University Graduate School of Medicine. “Previous studies in Caucasian populations found overlap in pathogenic CNVs between the two disorders, but their analyses were limited to a small number of genes and CNV loci.”
Autism spectrum disorder and schizophrenia have complex inheritance patterns, with multiple genetic and environmental factors influencing disease risk. Available evidence points to genetic overlap between the two clinically distinct disorders. For example, they tend to co-occur at a higher rate than would be expected in the general population, and a large epidemiological study showed that a family history of schizophrenia in first-degree relatives is a risk factor for autism spectrum disorder. In particular, previous studies have revealed that these two disorders are associated with an increased burden of CNVs, and that rare CNVs in specific loci are shared risk factors for both disorders.
Check out this fascinating interview with Professor Bruce Hollis, a pioneer in vitamin D research and an expert on vitamin D deficiency.
DATA: https://www.townsendletter.com/e-lett… Welcome, Professor Bruce Hollis! 0:53 The 2 systems in the body that use vitamin D 2:40 The forms of vitamin D 8:30 The problem with vitamin D research in the United States 15:45 What are normal vitamin D levels? 18:47 Vitamin D and cancer 25:35 Is vitamin D stored in your fat? 27:03 Vitamin D and your arteries 28:44 Vitamin D and lactation 34:11 Vitamin D and magnesium 36:43 Vitamin D toxicity 42:06 How did you begin your research on vitamin D? 49:30 Final thoughts Please join me in welcoming Professor Bruce Hollis! Professor Hollis’ research has provided a new understanding of the importance of vitamin D and its full range of functions. Vitamin D has been understood as an essential nutrient for skeletal integrity and maintaining blood calcium levels. As microbiology and research developed, researchers found that many cells that had nothing to do with the skeleton could respond to vitamin D, including cancer and immune cells. Vitamin D exists in different forms inside the body. When you take a supplement or sunlight hits your skin, you’re dealing with the inactive form of vitamin D. It is then turned into a compound called 25-hydroxy vitamin D, the intermediate form of vitamin D that stays in the blood for weeks. This form is picked up in blood tests but isn’t easily accessible by the tissues that might need it. The final form of vitamin D is one of the most potent hormones, 125 di-hydroxy vitamin D. Vitamin D is converted into the active form in the kidney but can also be converted inside the cells. The vast majority of studies substantiating our information on vitamin D in the U.S. have several problems and have produced inaccurate results. There is also no agreed-upon range on “normal” vitamin D levels—or what levels are considered a vitamin D deficiency. Professor Hollis has conducted research and has seen significant results using vitamin D to prevent birth complications in women in Iran, in patients with low-grade prostate cancer, and in lactation. He also explains the importance of magnesium, a key cofactor for vitamin D metabolism. Professor Hollis wants people to understand that few physicians recommend or acknowledge the benefits of vitamin D because national organizations have yet to properly understand and recognize them. Dr. Eric Berg DC Bio: Dr. Berg, age 59, is a chiropractor who specializes in Healthy Ketosis & Intermittent Fasting. He is the author of the best-selling book The Healthy Keto Plan, and is the Director of Dr. Berg Nutritionals. He no longer practices, but focuses on health education through social media. Follow Me On Social Media: Facebook: https://bit.ly/FB-DrBerg Instagram: https://bit.ly/IG-DrBerg Listen to my podcast: https://bit.ly/drberg-podcast TikTok: https://bit.ly/TikTok-DrBerg Disclaimer: Dr. Eric Berg received his Doctor of Chiropractic degree from Palmer College of Chiropractic in 1988. His use of “doctor” or “Dr.” in relation to himself solely refers to that degree. Dr. Berg is a licensed chiropractor in Virginia, California, and Louisiana, but he no longer practices chiropractic in any state and does not see patients, so he can focus on educating people as a full-time activity, yet he maintains an active license. This video is for general informational purposes only. It should not be used to self-diagnose, and it is not a substitute for a medical exam, cure, treatment, diagnosis, prescription, or recommendation. It does not create a doctor-patient relationship between Dr. Berg and you. You should not make any change in your health regimen or diet before first consulting a physician and obtaining a medical exam, diagnosis, and recommendation. Always seek the advice of a physician or other qualified health provider with any questions you may have regarding a medical condition. #keto #ketodiet #weightloss #ketolifestyle Thanks for watching! I hope this increases your awareness about the importance of vitamin D and addressing vitamin D deficiency. I’ll see you in the next video.
0:00 Welcome, Professor Bruce Hollis! 0:53 The 2 systems in the body that use vitamin D 2:40 The forms of vitamin D 8:30 The problem with vitamin D research in the United States. 15:45 What are normal vitamin D levels? 18:47 Vitamin D and cancer. 25:35 Is vitamin D stored in your fat? 27:03 Vitamin D and your arteries. 28:44 Vitamin D and lactation. 34:11 Vitamin D and magnesium. 36:43 Vitamin D toxicity. 42:06 How did you begin your research on vitamin D? 49:30 Final thoughts.
Please join me in welcoming Professor Bruce Hollis! Professor Hollis’ research has provided a new understanding of the importance of vitamin D and its full range of functions.
Vitamin D has been understood as an essential nutrient for skeletal integrity and maintaining blood calcium levels. As microbiology and research developed, researchers found that many cells that had nothing to do with the skeleton could respond to vitamin D, including cancer and immune cells.
Vitamin D exists in different forms inside the body. When you take a supplement or sunlight hits your skin, you’re dealing with the inactive form of vitamin D. It is then turned into a compound called 25-hydroxy vitamin D, the intermediate form of vitamin D that stays in the blood for weeks. This form is picked up in blood tests but isn’t easily accessible by the tissues that might need it.



{kind=link}
{kind=link}