Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=CGiDqhSdLHkPlease support this podcast by checking out our sponsors:- NetSuite: http://nets…
Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=CGiDqhSdLHkPlease support this podcast by checking out our sponsors:- NetSuite: http://nets…

In a new forward-looking Essay, P’aivi T’orm’a highlights the significance and impact of quantum geometry for the future of physics research.
Posted in computing, media & arts, quantum physics
How do we go from 100 to 200 to 1000? PASQAL, a quantum computing startup, is using LASERS. They’ve demonstrated 100 and 200 qubit systems, now they’re talking about making 1000. Here’s the mockup of their system.
———————-
Need POTATO merch? There’s a chip for that!
http://merch.techtechpotato.com.
http://more-moore.com : Sign up to the More Than Moore Newsletter.
https://www.patreon.com/TechTechPotato : Patreon gets you access to the TTP Discord server!
Follow Ian on Twitter at http://twitter.com/IanCutress.
Follow TechTechPotato on Twitter at http://twitter.com/TechTechPotato.
If you’re in the market for something from Amazon, please use the following links. TTP may receive a commission if you purchase anything through these links.
Amazon USA : https://geni.us/AmazonUS-TTP
Amazon UK : https://geni.us/AmazonUK-TTP
Amazon CAN : https://geni.us/AmazonCAN-TTP
Amazon GER : https://geni.us/AmazonDE-TTP
Amazon Other : https://geni.us/TTPAmazonOther.
Ending music: https://www.youtube.com/watch?v=2N0tmgau5E4

Building a plane while flying it isn’t typically a goal for most, but for a team of Harvard-led physicists that general idea might be a key to finally building large-scale quantum computers.
Described in a new paper in Nature, the research team, which includes collaborators from QuEra Computing, MIT, and the University of Innsbruck, developed a new approach for processing quantum information that allows them to dynamically change the layout of atoms in their system by moving and connecting them with each other in the midst of computation.
This ability to shuffle the qubits (the fundamental building blocks of quantum computers and the source of their massive processing power) during the computation process while preserving their quantum state dramatically expands processing capabilities and allows for self-correction of errors. Clearing this hurdle marks a major step toward building large-scale machines that leverage the bizarre characteristics of quantum mechanics and promise to bring about real-world breakthroughs in material science, communication technologies, finance, and many other fields.
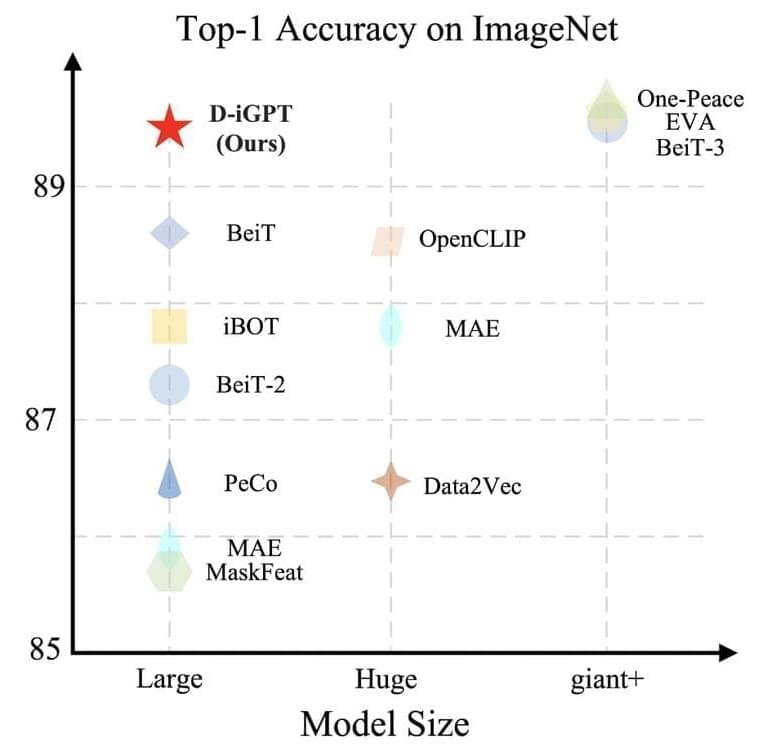
Natural language processing (NLP) has entered a transformational period with the introduction of Large Language Models (LLMs), like the GPT series, setting new performance standards for various linguistic tasks. Autoregressive pretraining, which teaches models to forecast the most likely tokens in a sequence, is one of the main factors causing this amazing achievement. Because of this fundamental technique, the models can absorb a complex interaction between syntax and semantics, contributing to their exceptional ability to understand language like a person. Autoregressive pretraining has substantially contributed to computer vision in addition to NLP.
In computer vision, autoregressive pretraining was initially successful, but subsequent developments have shown a sharp paradigm change in favor of BERT-style pretraining. This shift is noteworthy, especially in light of the first results from iGPT, which showed that autoregressive and BERT-style pretraining performed similarly across various tasks. However, because of its greater effectiveness in visual representation learning, subsequent research has come to prefer BERT-style pretraining. For instance, MAE shows that a scalable approach to visual representation learning may be as simple as predicting the values of randomly masked pixels.
In this work, the Johns Hopkins University and UC Santa Cruz research team reexamined iGPT and questioned whether autoregressive pretraining can produce highly proficient vision learners, particularly when applied widely. Two important changes are incorporated into their process. First, the research team “tokenizes” photos into semantic tokens using BEiT, considering images are naturally noisy and redundant. This modification shifts the focus of the autoregressive prediction from pixels to semantic tokens, allowing for a more sophisticated comprehension of the interactions between various picture areas. Secondly, the research team adds a discriminative decoder to the generative decoder, which autoregressively predicts the subsequent semantic token.
A biocomputing system consisting of living brain cells learned to recognise the voice of one individual from hundreds of sound clips.

In the ever-evolving landscape of artificial intelligence, a seismic shift is unfolding at OpenAI, and it involves more than just lines of code. The reported ‘superintelligence’ breakthrough has sent shockwaves through the company, pushing the boundaries of what we thought was possible and raising questions that extend far beyond the realm of algorithms.
Imagine a breakthrough so monumental that it threatens to dismantle the very fabric of the company that achieved it. OpenAI, the trailblazer in artificial intelligence, finds itself at a crossroads, dealing not only with technological advancement but also with the profound ethical and existential implications of its own creation – ‘superintelligence.’
The Breakthrough that Nearly Broke OpenAI: The Information’s revelation about a Generative AI breakthrough, capable of unleashing ‘superintelligence’ within this decade, sheds light on the internal disruption at OpenAI. Spearheaded by Chief Scientist Ilya Sutskever, the breakthrough challenges conventional AI training, allowing machines to solve problems they’ve never encountered by reasoning with cleaner and computer-generated data.

The 22nd century will make the 20th century look like Neolithic.
The world as we know it is predicted to unrecognizable by 2100 due to technological advancements that will move humans underground and have AI make our decisions.
 How do we go from 100 to 200 to 1000? PASQAL, a quantum computing startup, is using LASERS. They’ve demonstrated 100 and 200 qubit systems, now they’re talking about making 1000. Here’s the mockup of their system.
How do we go from 100 to 200 to 1000? PASQAL, a quantum computing startup, is using LASERS. They’ve demonstrated 100 and 200 qubit systems, now they’re talking about making 1000. Here’s the mockup of their system.