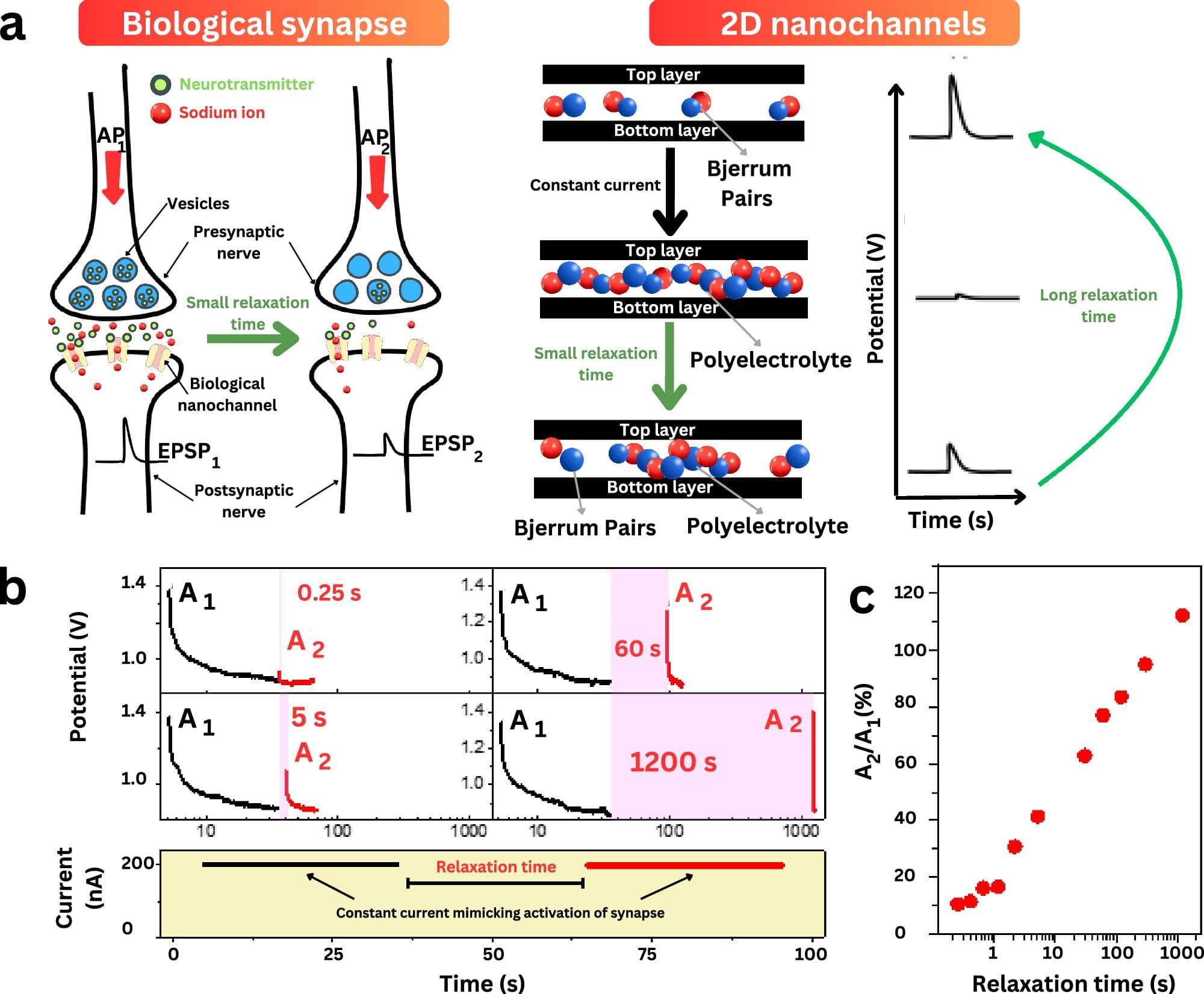
Researchers at The University of Manchester’s National Graphene Institute have developed a new class of programmable nanofluidic memristors that mimic the memory functions of the human brain, paving the way for next-generation neuromorphic computing.
In a study published in Nature Communications, scientists from the National Graphene Institute, Photon Science Institute and the Department of Physics and Astronomy have demonstrated how two-dimensional (2D) nanochannels can be tuned to exhibit all four theoretically predicted types of memristive behavior, something never before achieved in a single device.
This study not only reveals new insights into ionic memory mechanisms but also has the potential to enable emerging applications in low-power ionic logic, neuromorphic components, and adaptive chemical sensing.