Scientists have uncovered “Quipu,” the largest known galactic structure, stretching 1.4 billion light-years. This discovery reshapes cosmic mapping and affects key measurements of the universe’s expansion.
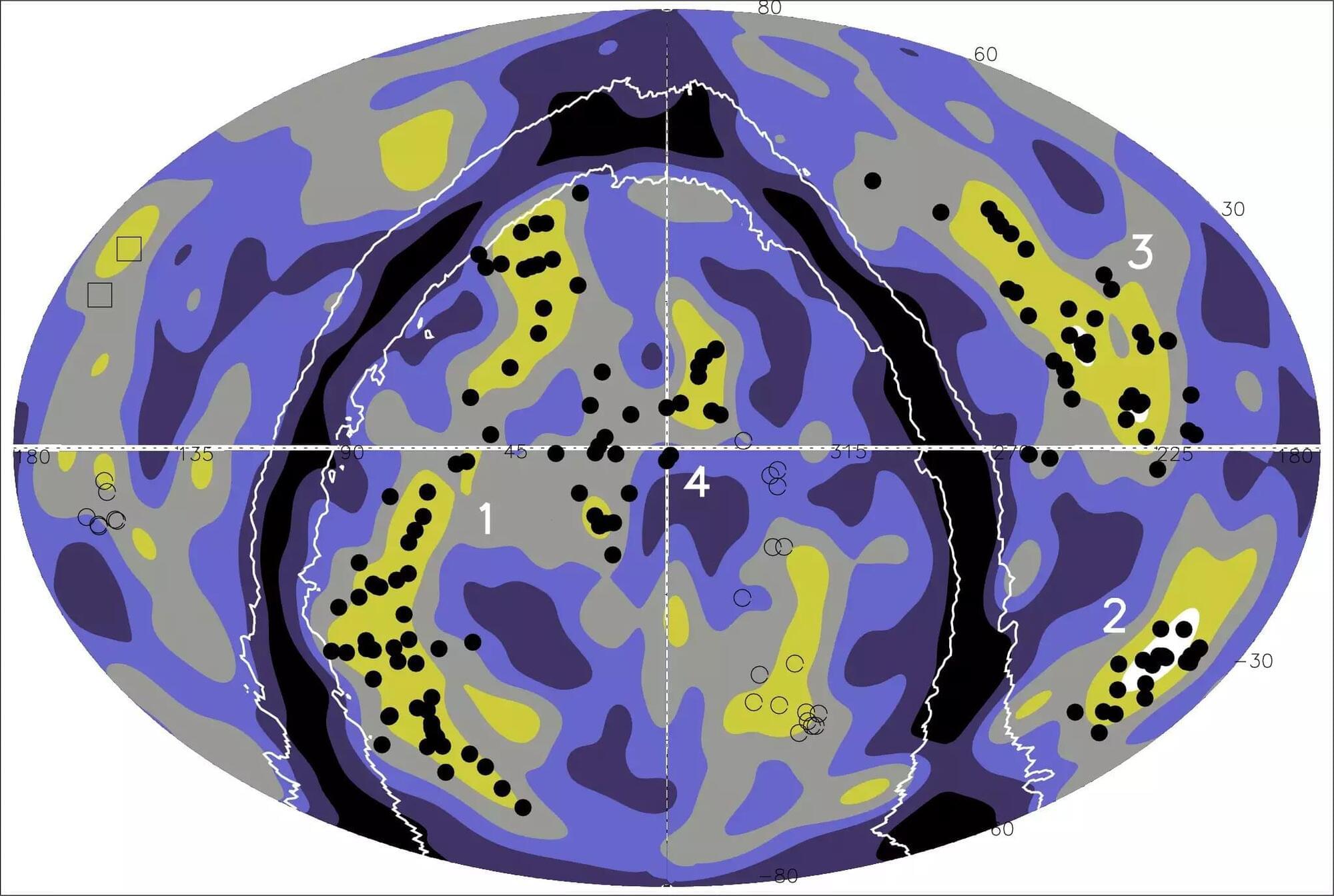
A team of scientists has identified the largest cosmic superstructure ever reliably measured. The discovery was made while mapping the nearby universe using galaxy clusters detected in the ROSAT X-ray satellite’s sky survey. Spanning approximately 1.4 billion light-years, this structure — primarily composed of dark matter — is the largest known formation in the universe to date. The research was led by scientists from the Max Planck Institute for Extraterrestrial Physics and the Max Planck Institute for Physics, in collaboration with colleagues from Spain and South Africa.
A Vastly Structured Universe