One of the variables in TD algorithms is called reward prediction error (RPE), which is the difference between the discounted predicted reward at the current state and the discounted predicted reward plus the actual reward at the next state. TD learning theory gained traction in neuroscience once it was demonstrated that firing patterns of dopaminergic neurons in the ventral tegmental area (VTA) during reinforcement learning resemble RPE5,9,10.
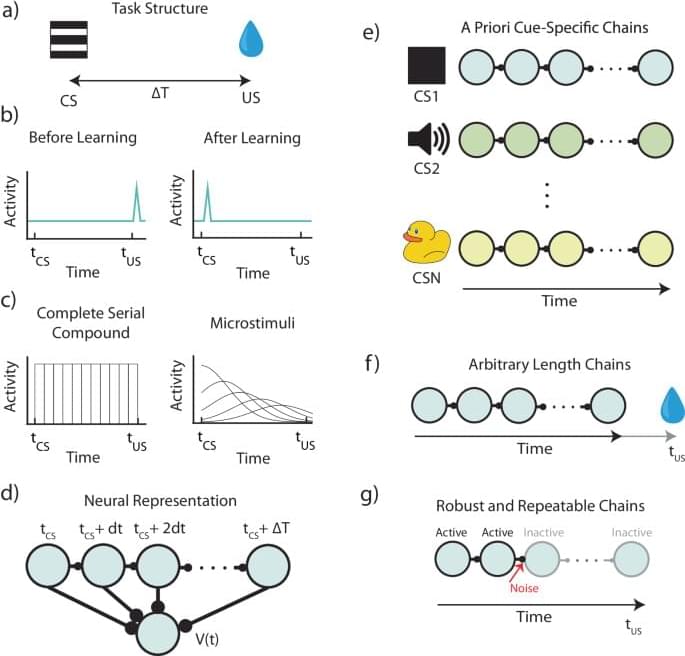
Implementations of TD using computer algorithms are straightforward, but are more complex when they are mapped onto plausible neural machinery11,12,13. Current implementations of neural TD assume a set of temporal basis-functions13,14, which are activated by external cues. For this assumption to hold, each possible external cue must activate a separate set of basis-functions, and these basis-functions must tile all possible learnable intervals between stimulus and reward.
In this paper, we argue that these assumptions are unscalable and therefore implausible from a fundamental conceptual level, and demonstrate that some predictions of such algorithms are inconsistent with various established experimental results. Instead, we propose that temporal basis functions used by the brain are themselves learned. We call this theoretical framework: Flexibly Learned Errors in Expected Reward, or FLEX for short. We also propose a biophysically plausible implementation of FLEX, as a proof-of-concept model. We show that key predictions of this model are consistent with actual experimental results but are inconsistent with some key predictions of the TD theory.