Randy Kirk
Get the latest international news and world events from around the world.
How researchers discovered specific brain cells that enable intelligent behavior
For decades, neuroscientists have developed mathematical frameworks to explain how brain activity drives behavior in predictable, repetitive scenarios, such as while playing a game. These algorithms have not only described brain cell activity with remarkable precision but also helped develop artificial intelligence with superhuman achievements in specific tasks, such as playing Atari or Go.
Yet these frameworks fall short of capturing the essence of human and animal behavior: our extraordinary ability to generalize, infer and adapt. Our study, published in Nature late last year, provides insights into how brain cells in mice enable this more complex, intelligent behavior.
Unlike machines, humans and animals can flexibly navigate new challenges. Every day, we solve new problems by generalizing from our knowledge or drawing from our experiences. We cook new recipes, meet new people, take a new path—and we can imagine the aftermath of entirely novel choices.
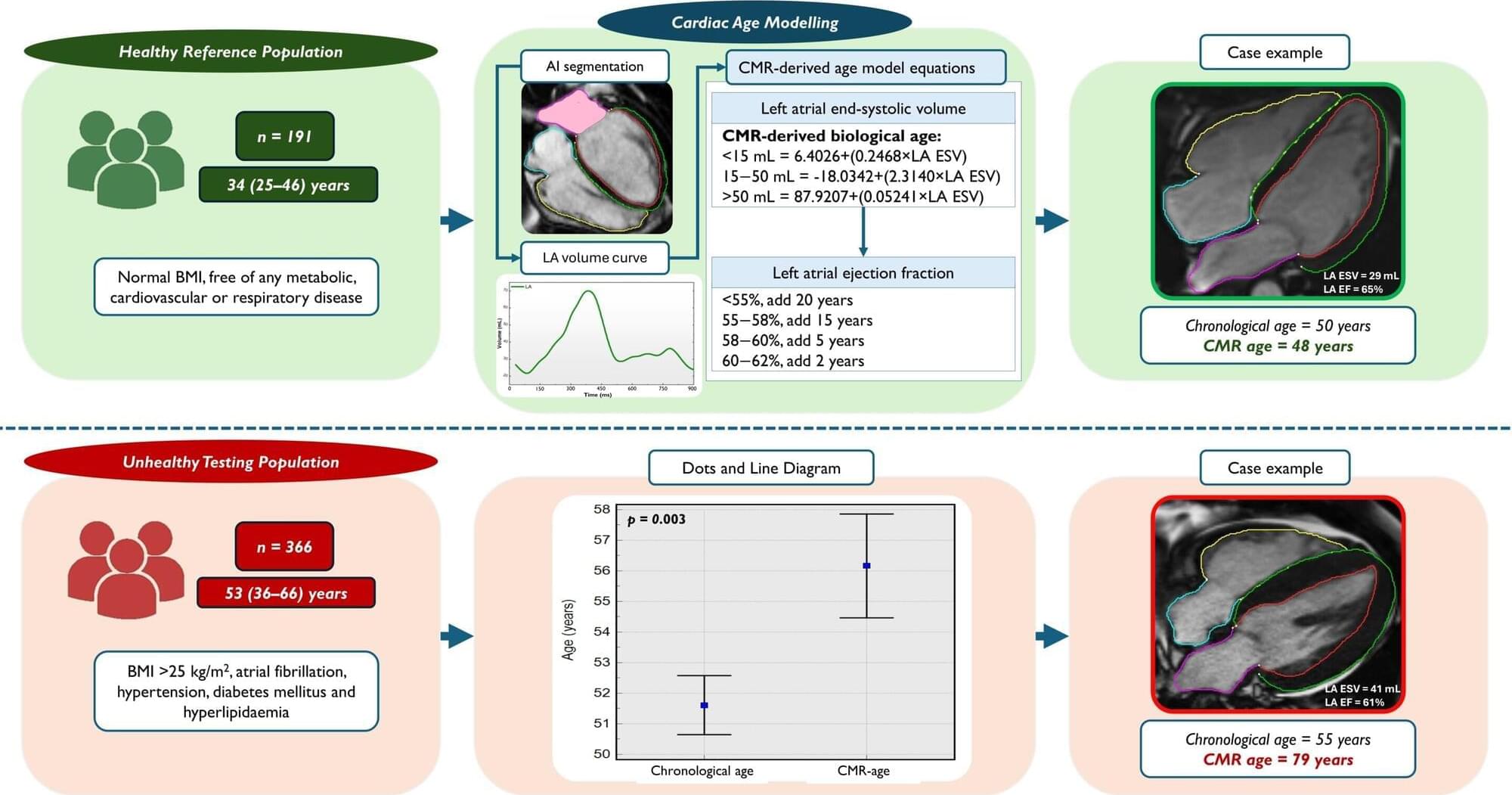
Is your heart aging too fast? MRI technique reveals how unhealthy lifestyles can add decades
Scientists at the University of East Anglia (UEA) have developed a new way of uncovering the “true age” of a heart using MRI.
Research accepted for publication European Heart Journal Open shows how an MRI scan can reveal your heart’s functional age—and how unhealthy lifestyles can dramatically accelerate this figure. The paper is titled “Cardiac MRI Markers of Ageing: A Multicentre, Cross-sectional Cohort Study.”
It is hoped that the findings could transform how heart disease is diagnosed—offering a lifeline to millions by catching problems before they become deadly.

World First: Engineers Train AI at Lightspeed
Breakthrough light-powered chip speeds up AI training and reduces energy consumption.
Engineers at Penn have developed the first programmable chip capable of training nonlinear neural networks using light—a major breakthrough that could significantly accelerate AI training, lower energy consumption, and potentially lead to fully light-powered computing systems.
Unlike conventional AI chips that rely on electricity, this new chip is photonic, meaning it performs calculations using beams of light. Published in Nature Photonics.
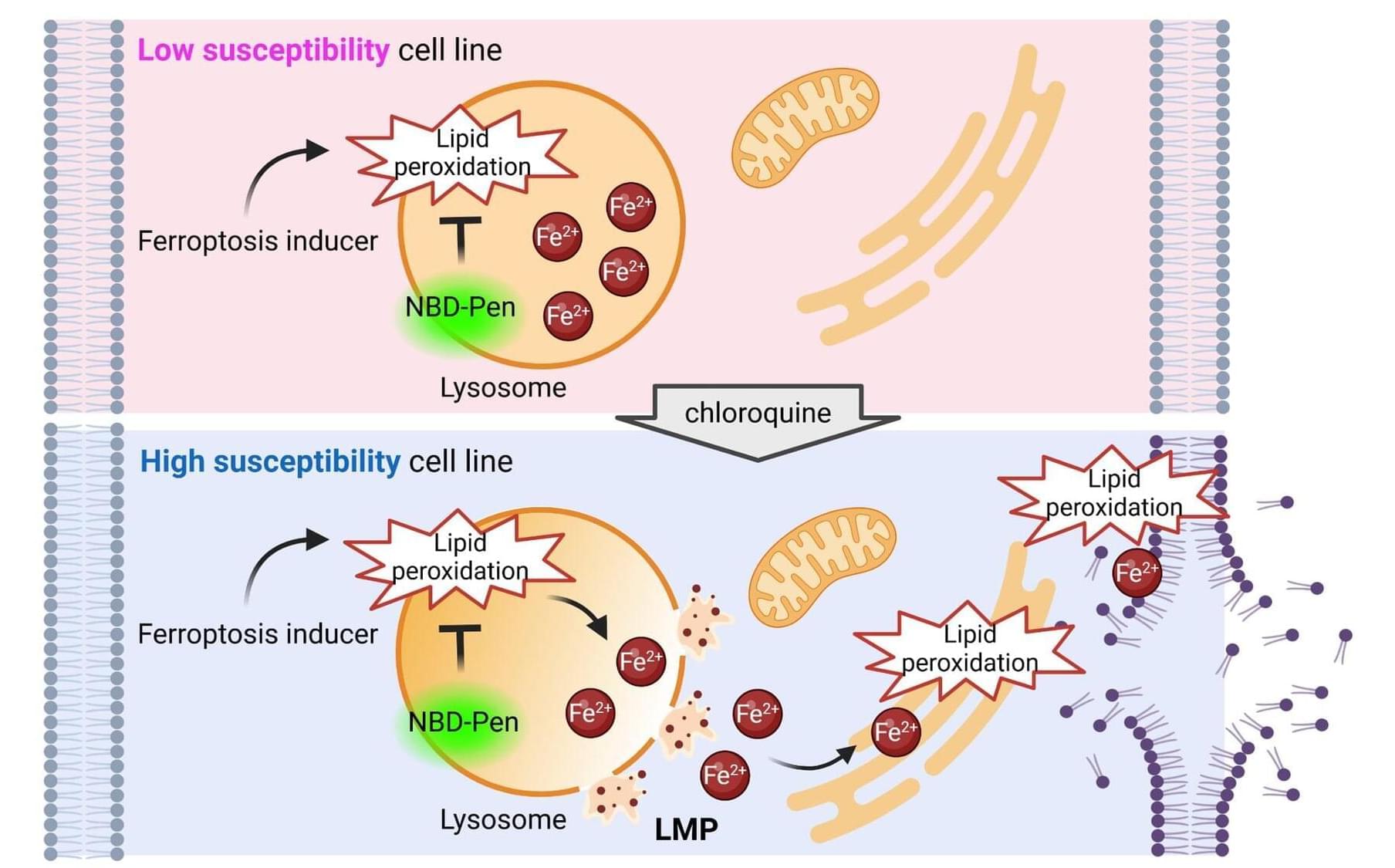
Lysosome destabilization found to drive iron-dependent cell death in cancer
The duplication and division of cells is critical to keeping all multicellular organisms alive. But the opposite process is equally important: cell death. Controlled death of cells, or programmed cell death, is also necessary for the proper development and function of the body. It has also been a focus of researchers developing treatments for cancer by finding ways to activate the cell death of cancer cells themselves.
Ferroptosis is a recently discovered form of programmed cell death and has been a promising target for the development of cancer treatments. It is mediated by iron molecules, with the cell dying through the degradation of the phospholipid bilayer by oxidation, a process called lipid peroxidation. However, recent studies have shown that certain cancer cells are less susceptible to ferroptosis, raising concerns that this resistance could pose a barrier to future therapeutics.
In a paper published in Nature Communications, researchers from Kyushu University, using cultured cells and mice, found that the lipid peroxidation of the lysosomes—the organelle responsible for degrading and recycling molecules in a cell—plays a critical role in the execution of ferroptosis.

Antimicrobial Use in Companion Animals
Antimicrobial resistance (AMR) presents a serious challenge in today’s world. The use of antimicrobials (AMU) significantly contributes to the emergence and spread of resistant bacteria. Companion animals gain recognition as potential reservoirs and vectors for transmitting resistant microorganisms to both humans and other animals. The full extent of this transmission remains unclear, which is particularly concerning given the substantial and growing number of households with companion animals. This situation highlights critical knowledge gaps in our understanding of risk factors and transmission pathways for AMR transfer between companion animals and humans. Moreover, there’s a significant lack of information regarding AMU in everyday veterinary practices for companion animals.

Making AI models more trustworthy for high-stakes contexts, like classifying diseases in medical images
Antimicrobial resistance (AMR) presents a serious challenge in today’s world. The use of antimicrobials (AMU) significantly contributes to the emergence and spread of resistant bacteria. Companion animals gain recognition as potential reservoirs and vectors for transmitting resistant microorganisms to both humans and other animals. The full extent of this transmission remains unclear, which is particularly concerning given the substantial and growing number of households with companion animals. This situation highlights critical knowledge gaps in our understanding of risk factors and transmission pathways for AMR transfer between companion animals and humans. Moreover, there’s a significant lack of information regarding AMU in everyday veterinary practices for companion animals. The exploration and development of alternative therapeutic approaches to antimicrobial treatments of companion animals also represents a research priority. To address these pressing issues, this Reprint aims to compile and disseminate crucial additional knowledge. It serves as a platform for relevant research studies and reviews, shedding light on the complex interplay between AMU, AMR, and the role of companion animals in this global health challenge. This Reprint is especially addressed to companion animal veterinary practitioners as well as all researchers working on the field of AMR in both animals and humans, from a One Health perspective.
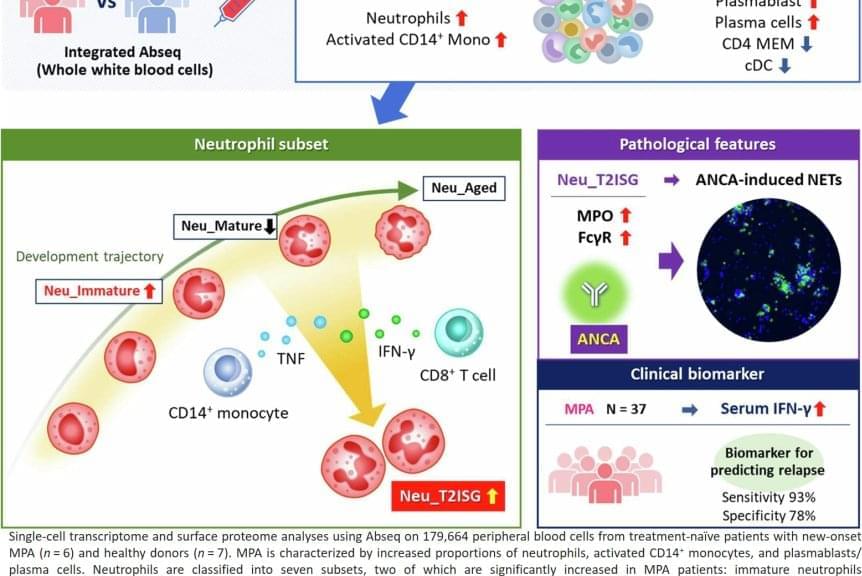
Predicting relapse of autoimmune small vessel vasculitis
Neutrophils, one of the immune system warriors that were thought to be all the same, turn out to be diverse. Unfortunately, these cells are also active in autoimmune diseases. New research has found that a certain subpopulation of these white blood cells can predict disease relapse at an early stage, which may enable improved personalized treatment.
In a study published in Nature Communications, a multi-institutional research team investigated which cell types dominate the blood of patients at the early stage of anti-neutrophil cytoplasmic antibody (ANCA)-associated vasculitis, which is caused by inflammation in the blood vessels and can disrupt organ function.
“Figuring out the mechanism of this disease, which is poorly understood, will help us understand autoimmune dysregulation in neutrophils. This could aid in the development of new drugs tailored for each patient,” says the lead author of the study. “Because we want to understand the dynamics of neutrophil behavior at the cell level in the early stages of the disease, for this study we recruited new patients that had not yet been treated.”