The idea of objects seamlessly disappearing, not just in controlled laboratory environments but also in real-world scenarios, has long captured the popular imagination. This concept epitomizes the trajectory of human civilization, from primitive camouflage techniques to the sophisticated metamaterial-based cloaks of today.
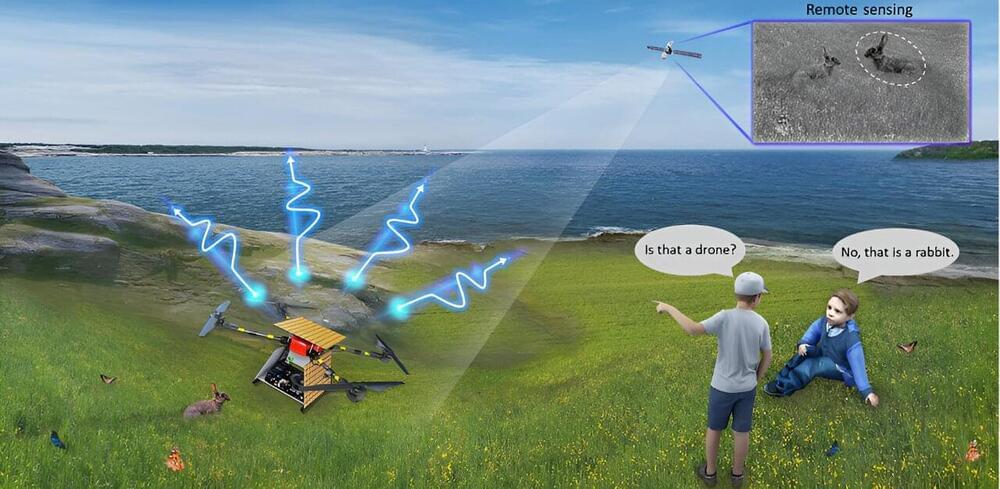
Recently, this goal was further highlighted in Science, as one of the “125 questions: exploration and discovery.” Researchers from Zhejiang University have made strides in this direction by demonstrating an intelligent aero amphibious invisibility cloak. This cloak can maintain invisibility amidst dynamic environments, neutralizing external stimuli.
Despite decades of research and the emergence of numerous invisibility cloak prototypes, achieving an aero amphibious cloak capable of manipulating electromagnetic scattering in real-time against ever-changing landscapes remains a formidable challenge. The hurdles are multifaceted, ranging from the need for complex-amplitude tunable metasurfaces to the absence of intelligent algorithms capable of addressing inherent issues such as non-uniqueness and incomplete inputs.