Who was Edsger Dijkstra? Discover how his warnings on complexity, algorithms & control connect directly to today’s debates on AI and the Singularity.

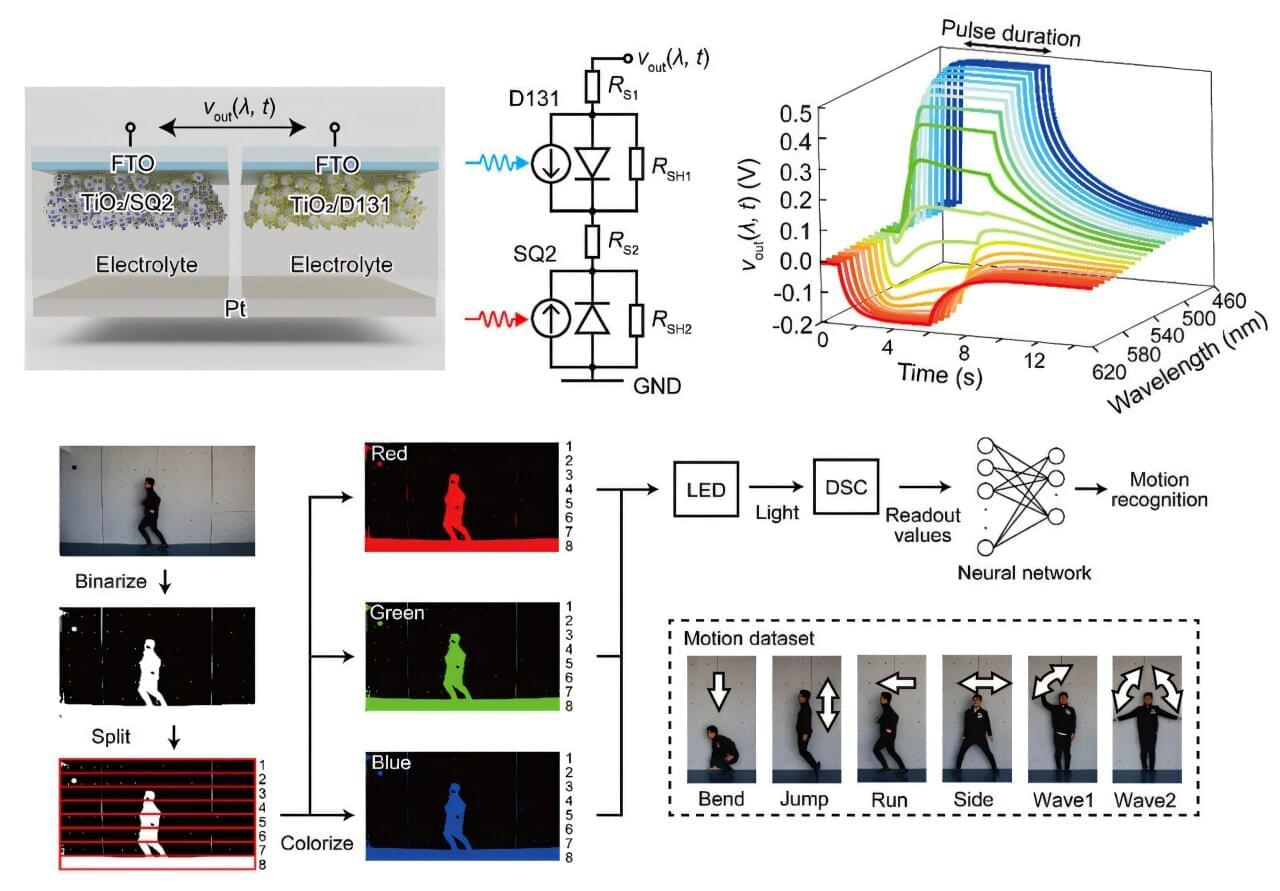
As artificial intelligence and smart devices continue to evolve, machine vision is taking an increasingly pivotal role as a key enabler of modern technologies. Unfortunately, despite much progress, machine vision systems still face a major problem: Processing the enormous amounts of visual data generated every second requires substantial power, storage, and computational resources. This limitation makes it difficult to deploy visual recognition capabilities in edge devices, such as smartphones, drones, or autonomous vehicles.
Interestingly, the human visual system offers a compelling alternative model. Unlike conventional machine vision systems that have to capture and process every detail, our eyes and brain selectively filter information, allowing for higher efficiency in visual processing while consuming minimal power.
Neuromorphic computing, which mimics the structure and function of biological neural systems, has thus emerged as a promising approach to overcome existing hurdles in computer vision. However, two major challenges have persisted. The first is achieving color recognition comparable to human vision, whereas the second is eliminating the need for external power sources to minimize energy consumption.
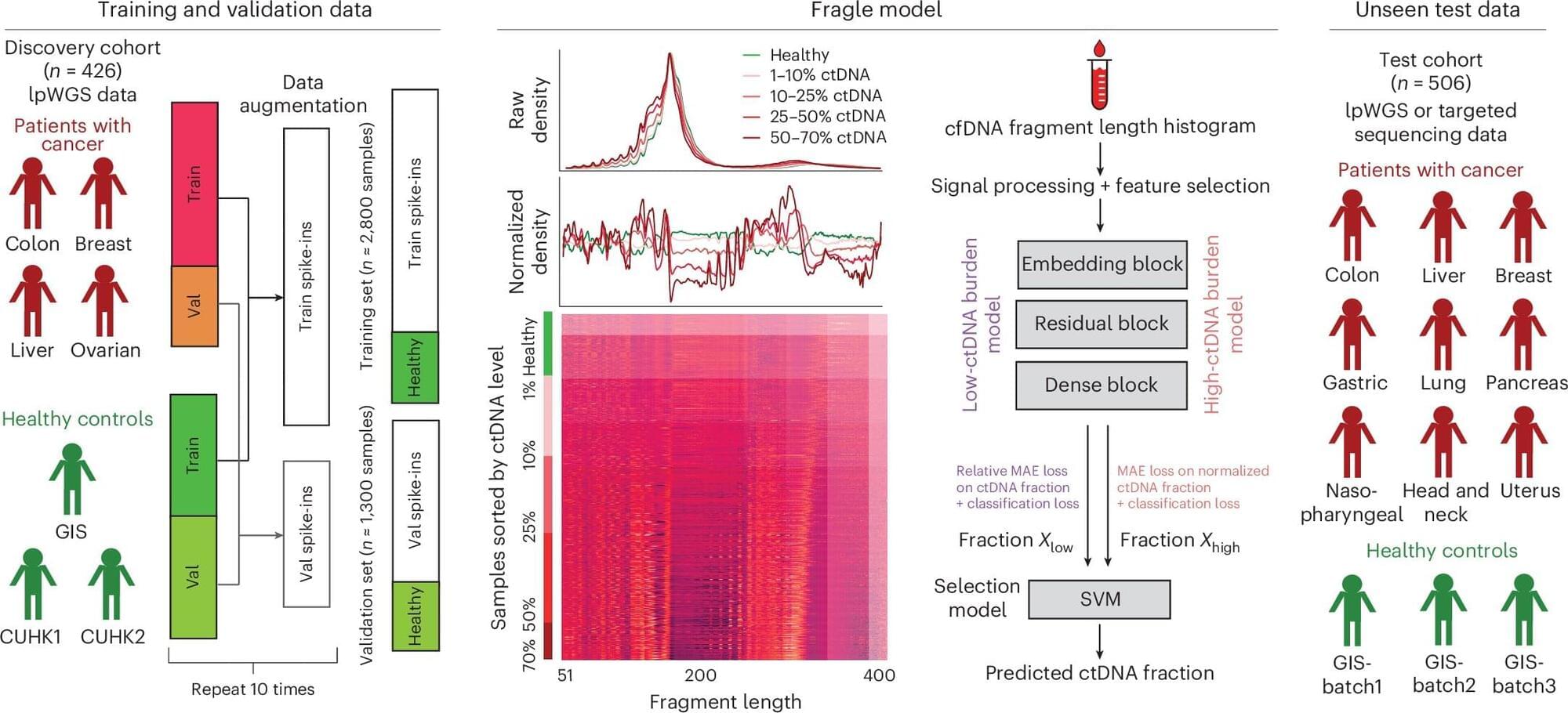
Scientists from the A*STAR Genome Institute of Singapore (A*STAR GIS) have developed a new artificial intelligence (AI)-based method called “Fragle” that makes tracking cancer easier and faster using blood tests.
Requiring only a small blood sample, this method analyzes the size of DNA fragments in the blood to reveal distinct patterns that differentiate cancer DNA from healthy DNA, helping doctors track cancer treatment response more accurately and frequently. The research was published in Nature Biomedical Engineering in March 2025.
Existing methods for measuring cancer DNA in the blood, also known as circulating tumor DNA (ctDNA), often require complex and expensive DNA sequencing to screen for common cancer mutations. However, because cancer mutations vary between patients, test results can be inconsistent, making it difficult for doctors to track cancer treatment response with blood tests effectively.


ChatGPT-maker OpenAI has enlisted the legendary designer behind the iPhone to create an irresistible gadget for using generative artificial intelligence (AI).
The ability to engage digital assistants as easily as speaking with friends is being built into eyewear, speakers, computers and smartphones, but some argue that the Age of AI calls for a transformational new gizmo.
“The products that we’re using to deliver and connect us to unimaginable technology are decades old,” former Apple chief design officer Jony Ive said when his alliance with OpenAI was announced.



As part of the expansion, Yaskawa will begin manufacturing robots in Franklin. The company purchased a more than 200,000-square-foot building in Franklin in 2023 for $20 million. The site was previously used by a packaging company.
The Wisconsin Economic Development Corp. is supporting the project with up to $18 million dollars in tax credits. Officials say the amount of credits awarded will be contingent upon hitting job creation and investment targets.
In a statement, Gov. Tony Evers said the expansion would bring millions of dollars of investment and hundreds of “high-quality” jobs to southeast Wisconsin.
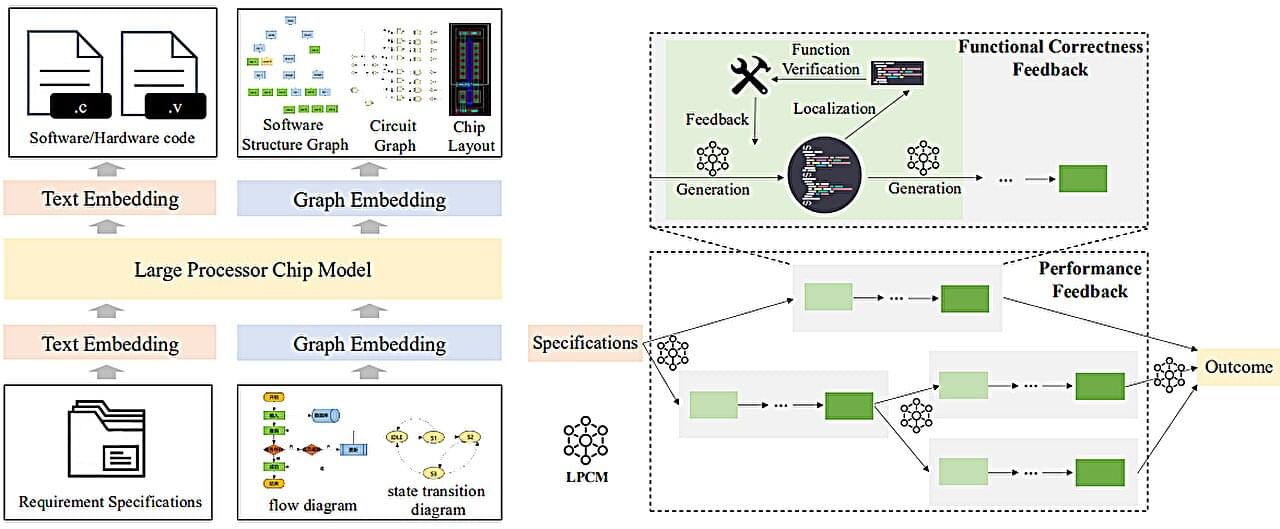
A team of engineers, AI specialists and chip design researchers at the Chinese Academy of Sciences has designed, built and tested what they are describing as the first AI-based chip design system. The group has published a paper describing their system, called QiMeng, on the arXiv preprint server.
Over the past several decades, integrated circuit makers have developed systems for developing processor chips for computers, smartphones and other electronic devices. Such systems tend to be made up of large teams of highly skilled people who can take design ideas (such as faster computing or running AI apps) and turn them into physical designs that can be fabricated in specially designed factories. The process is notoriously slow and expensive.
More recently, computer and device makers have been looking for ways to speed up the process and to allow for more flexibility—some may want a chip that can do just one thing, for example, but do it really well. In this new study, the team in China has applied AI to the problem.

More people believe misinformation about electric vehicles (EVs) than disagree with it, according to surveys of four countries, including Australia, Germany, Austria, and the US. The survey found having a conspiracy mentality was the main factor influencing such beliefs, the authors say.
The main misinformation-related concerns for Australians included that EVs are more likely to catch fire, that EVs are intentionally complex to prevent DIY, and that batteries are deliberately non-upgradeable. The authors also found that fact sheets and dialogues with AI-chatbots helped reduce belief in misinformation and increased pro-EV policy support and purchase intentions.
A University of Queensland-led study published in the journal Nature Energy has found misinformation about electric vehicles (EVs) has taken root in society and is primarily fueled by mistrust and conspiracy theories.