Yann LeCun, machine learning pioneer and head of AI at Meta, lays out a vision for AIs that learn about the world more like humans in a new study.
Category: robotics/AI – Page 1,720
Fluidic circuits add analog options for controlling soft robots
Add analog and air-driven to the list of control system options for soft robots.
In a study published online this week, robotics researchers, engineers and materials scientists from Rice University and Harvard University showed it is possible to make programmable, nonelectronic circuits that control the actions of soft robots by processing information encoded in bursts of compressed air.
“Part of the beauty of this system is that we’re really able to reduce computation down to its base components,” said Rice undergraduate Colter Decker, lead author of the study in the Proceedings of the National Academy of Sciences. He said electronic control systems have been honed and refined for decades, and recreating computer circuitry “with analogs to pressure and flow rate instead of voltage and current” made it easier to incorporate pneumatic computation.
Air-powered computer memory helps soft robot control movements
Engineers at UC Riverside have unveiled an air-powered computer memory that can be used to control soft robots. The innovation overcomes one of the biggest obstacles to advancing soft robotics: the fundamental mismatch between pneumatics and electronics. The work is published in the open-access journal, PLOS One.
Pneumatic soft robots use pressurized air to move soft, rubbery limbs and grippers and are superior to traditional rigid robots for performing delicate tasks. They are also safer for humans to be around. Baymax, the healthcare companion robot in the 2014 animated Disney film, Big Hero 6, is a pneumatic robot for good reason.
But existing systems for controlling pneumatic soft robots still use electronic valves and computers to maintain the position of the robot’s moving parts. These electronic parts add considerable cost, size, and power demands to soft robots, limiting their feasibility.
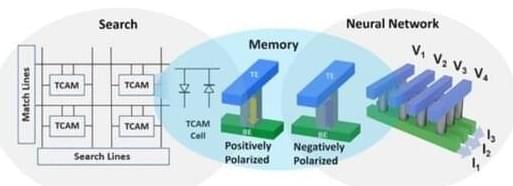
This new computer chip is ideal for AI
Artificial intelligence presents a major challenge to conventional computing architecture. In standard models, memory storage and computing take place in different parts of the machine, and data must move from its area of storage to a CPU or GPU for processing.
The problem with this design is that movement takes time. Too much time. You can have the most powerful processing unit on the market, but its performance will be limited as it idles waiting for data, a problem known as the “memory wall” or “bottleneck.”
When computing outperforms memory transfer, latency is unavoidable. These delays become serious problems when dealing with the enormous amounts of data essential for machine learning and AI applications.
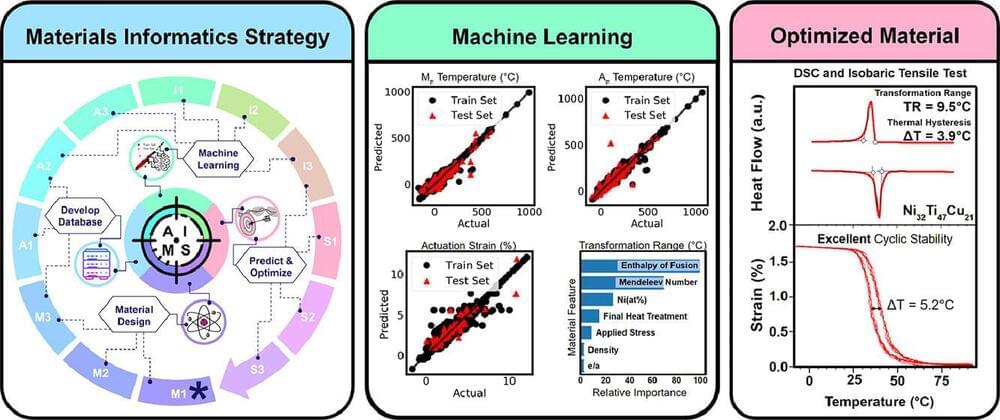
New shape memory alloy discovered through artificial intelligence framework
Researchers from the Department of Materials Science and Engineering at Texas A&M University have used an Artificial Intelligence Materials Selection framework (AIMS) to discover a new shape memory alloy. The shape memory alloy showed the highest efficiency during operation achieved thus far for nickel-titanium-based materials. In addition, their data-driven framework offers proof of concept for future materials development.
This study was recently published in the Acta Materialia journal.
Shape memory alloys are utilized in various fields where compact, lightweight and solid-state actuations are needed, replacing hydraulic or pneumatic actuators because they can deform when cold and then return to their original shape when heated. This unique property is critical for applications, such as airplane wings, jet engines and automotive components, that must withstand repeated, recoverable large-shape changes.
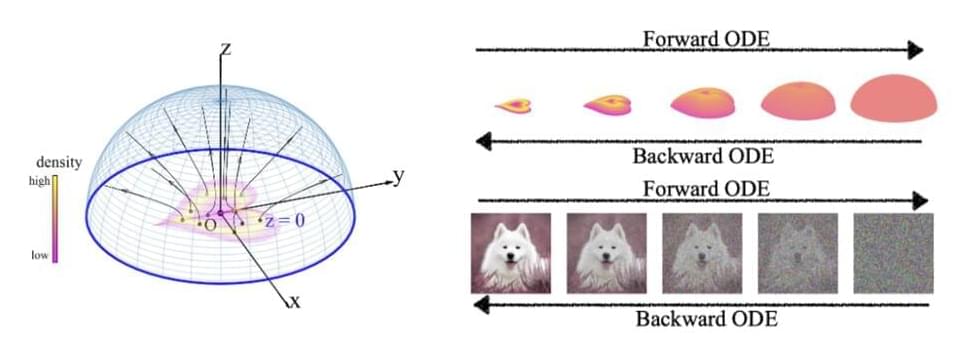
Latest Machine Learning Research at MIT Presents a Novel ‘Poisson Flow’ Generative Model (PFGM) That Maps any Data Distribution into a Uniform Distribution on a High-Dimensional Hemisphere
Deep generative models are a popular data generation strategy used to generate high-quality samples in pictures, text, and audio and improve semi-supervised learning, domain generalization, and imitation learning. Current deep generative models, however, have shortcomings such as unstable training objectives (GANs) and low sample quality (VAEs, normalizing flows). Although recent developments in diffusion and scored-based models attain equivalent sample quality to GANs without adversarial training, the stochastic sampling procedure in these models is sluggish. New strategies for securing the training of CNN-based or ViT-based GAN models are presented.
They suggest backward ODEsamplers (normalizing flow) accelerate the sampling process. However, these approaches have yet to outperform their SDE equivalents. We introduce a novel “Poisson flow” generative model (PFGM) that takes advantage of a surprising physics fact that extends to N dimensions. They interpret N-dimensional data items x (say, pictures) as positive electric charges in the z = 0 plane of an N+1-dimensional environment filled with a viscous liquid like honey. As shown in the figure below, motion in a viscous fluid converts any planar charge distribution into a uniform angular distribution.
A positive charge with z 0 will be repelled by the other charges and will proceed in the opposite direction, ultimately reaching an imaginary globe of radius r. They demonstrate that, in the r limit, if the initial charge distribution is released slightly above z = 0, this rule of motion will provide a uniform distribution for their hemisphere crossings. They reverse the forward process by generating a uniform distribution of negative charges on the hemisphere, then tracking their path back to the z = 0 planes, where they will be dispersed as the data distribution.

Tesla announces it’s moving away from ultrasonic sensors in favor of ‘Tesla Vision’
Tesla announced today that it is moving away from using ultrasonic sensors in its suite of Autopilot sensors in favor of its camera-only “Tesla Vision” system.
Last year, Tesla announced it would transition to its “Tesla Vision” Autopilot without radar and start producing vehicles without a front-facing radar.
Originally, the suite of Autopilot sensors – which Tesla claimed would include everything needed to achieve full self-driving capability eventually – included eight cameras, a front-facing radar, and several ultrasonic sensors all around its vehicles.
{kind=link}
Stretchy, Wearable Synaptic Transistor Turns Robotics Smarter
{kind=link}
A team of Penn State engineers has created a stretchy, wearable synaptic transistor that could turn robotics and wearable devices smarter. The device developed by the team works like neurons in the brain, sending signals to some cells and inhibiting others to enhance and weaken the devices’ memories.
The research was led by Cunjiang Yu, Dorothy Quiggle Career Development Associate Professor of Engineering Science and Mechanics and associate professor of biomedical engineering and of materials science and engineering.
The research was published in Nature Electronics.

AI-enabled imaging of retina’s vascular network can predict cardiovascular disease and death
AI-enabled imaging of the retina’s network of veins and arteries can accurately predict cardiovascular disease and death, without the need for blood tests or blood pressure measurement, finds research published online in the British Journal of Ophthalmology.
As such, it paves the way for a highly effective, non-invasive screening test for people at medium to high risk of circulatory disease that doesn’t have to be done in a clinic, suggest the researchers.
Circulatory diseases, including cardiovascular disease, coronary heart disease, heart failure and stroke, are major causes of ill health and death worldwide, accounting for 1 in 4 UK deaths alone.