{kind=link}
A team of researchers at MIT has created microscopic devices that perform machine-learning math using only the heat already present in electronics, achieving over 99% accuracy.
Category: robotics/AI – Page 163


Planes grounded as extreme solar radiation hits essential flight controls. 6,000 jets affected
The A320 involved suffered a flight-control issue that caused a sudden drop in altitude, leaving some passengers with non-life-threatening injuries. During the investigation, a vulnerability to solar flares emerged.
As the aviation industry grows more automated and electronics-dependent, understanding space-weather threats is increasingly vital.
Recent NASA studies suggest that space weather is becoming more intense and frequent, with the Sun currently in a stronger-than-expected activity cycle (solar cycle 25) and potentially entering a period of elevated activity that could last decades.
AGI Is Here: AI Legend Peter Norvig on Why it Doesn’t Matter Anymore
Are we chasing the wrong goal with Artificial General Intelligence, and missing the breakthroughs that matter now?
On this episode of Digital Disruption, we’re joined by former research director at Google and AI legend, Peter Norvig.
Peter is an American computer scientist and a Distinguished Education Fellow at the Stanford Institute for Human-Centered Artificial Intelligence (HAI). He is also a researcher at Google, where he previously served as Director of Research and led the company’s core search algorithms group. Before joining Google, Norvig headed NASA Ames Research Center’s Computational Sciences Division, where he served as NASA’s senior computer scientist and received the NASA Exceptional Achievement Award in 2001.He is best known as the co-author, alongside Stuart J. Russell, of Artificial Intelligence: A Modern Approach — the world’s most widely used textbook in the field of artificial intelligence.
Peter sits down with Geoff to separate facts from fiction about where AI is really headed. He explains why the hype around Artificial General Intelligence (AGI) misses the point, how today’s models are already “general,” and what truly matters most: making AI safer, more reliable, and human-centered. He discusses the rapid evolution of generative models, the risks of misinformation, AI safety, open-source regulation, and the balance between democratizing AI and containing powerful systems. This conversation explores the impact of AI on jobs, education, cybersecurity, and global inequality, and how organizations can adapt, not by chasing hype, but by aligning AI to business and societal goals. If you want to understand where AI actually stands, beyond the headlines, this is the conversation you need to hear.
In this episode:
00:00 Intro.
01:00 How AI evolved since Artificial Intelligence: A Modern Approach.
03:00 Is AGI already here? Norvig’s take on general intelligence.
06:00 The surprising progress in large language models.
08:00 Evolution vs. revolution.
10:00 Making AI safer and more reliable.
12:00 Lessons from social media and unintended consequences.
15:00 The real AI risks: misinformation and misuse.
18:00 Inside Stanford’s Human-Centered AI Institute.
20:00 Regulation, policy, and the role of government.
22:00 Why AI may need an Underwriters Laboratory moment.
24:00 Will there be one “winner” in the AI race?
26:00 The open-source dilemma: freedom vs. safety.
28:00 Can AI improve cybersecurity more than it harms it?
30:00 “Teach Yourself Programming in 10 Years” in the AI age.
33:00 The speed paradox: learning vs. automation.
36:00 How AI might (finally) change productivity.
38:00 Global economics, China, and leapfrog technologies.
42:00 The job market: faster disruption and inequality.
45:00 The social safety net and future of full-time work.
48:00 Winners, losers, and redistributing value in the AI era.
50:00 How CEOs should really approach AI strategy.
52:00 Why hiring a “PhD in AI” isn’t the answer.
54:00 The democratization of AI for small businesses.
56:00 The future of IT and enterprise functions.
57:00 Advice for staying relevant as a technologist.
59:00 A realistic optimism for AI’s future.
#ai #agi #humancenteredai #futureofwork #aiethics #innovation.
AI expert warns we’re close to extinction
Connor Leahy discusses the motivations of AGI corporations, how modern AI is “grown”, the need for a science of intelligence, the effects of AI on work, the radical implications of superintelligence, and what you might be able to do about all of this. https://www.thecompendium.ai 00:00 The AI Race 02:14 CEOs Lying 04:02 The Entente Strategy 06:12 AI is grown, not built 07:39 Jobs 10:47 Alignment 14:25 What should you do? Original Podcast: • Connor Leahy on Why Humanity Risks Extinct… Editing: https://zeino.tv/

World Modeling Workshop — Day 1
A fundamental desideratum of AI is the ability to model environment dynamics and transitions in response to both their own actions and external control signals. This capability, commonly referred to as world modeling (WM), is essential for prediction, planning, and generalization. Learning world models using deep learning has been an active area of research for nearly a decade. In recent years, the field has witnessed significant breakthroughs driven by advances in deep neural architectures and scalable learning paradigms. Multiple subfields, including self-supervised learning (SSL), generative modeling, reinforcement learning (RL), robotics, and large language models (LLMs), have tackled aspects of world modeling, often with different tools and methodologies. While these communities address overlapping challenges, they frequently operate in isolation. As a result, insights and progress in one area may go unnoticed in another, limiting opportunities for synthesis and collaboration. This workshop aims to bridge this gap between subfields of world modeling by fostering open dialogue, critical discussion, and cross-disciplinary exchange. By bringing together researchers from diverse backgrounds, from early-career researchers to established experts, we hope to establish a shared vocabulary, identify common challenges, and surface synergies that can move the field of world modeling forward.
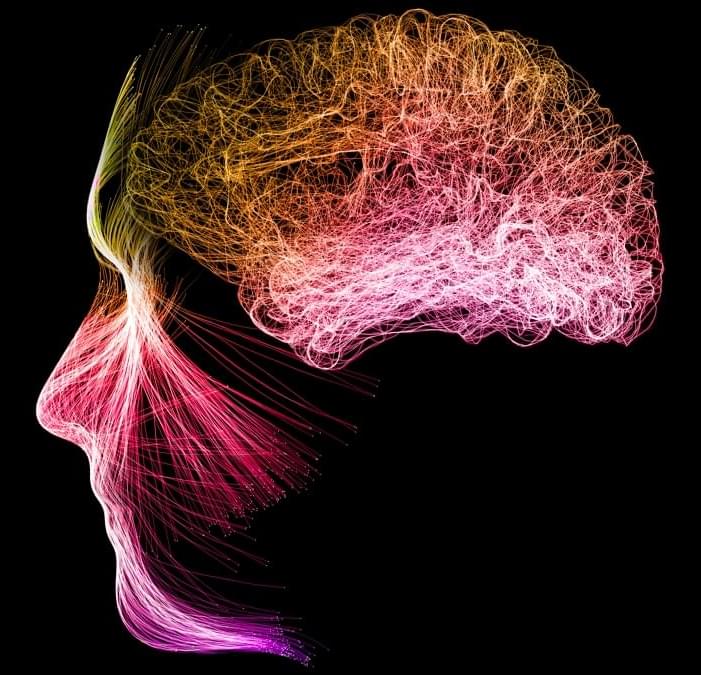
Meditation Can Reshape Your Brain Activity, Study Reveals
Meditation may calm the mind, but a recent study suggests it can also reshape brain activity by profoundly altering brain dynamics and increasing neural connections – somewhat similar to psychedelic substances.
As a result, meditation may help practitioners achieve a hypothesized state known as “brain criticality”, in which neural connections are neither too weak nor too strong, but at an optimal level for mental agility and function.
In the study, led by neurophysiologist Annalisa Pascarella of the Italian National Research Council, researchers used high-resolution brain scans and machine learning to examine how meditation can alter brain activity to achieve an equilibrium between neural chaos and order.

Satellite servicing startup Starfish taps Quindar for mission operations software
WASHINGTON — Quindar, a startup that provides mission management software for satellite operators, has been selected by satellite servicing company Starfish Space to support the first three missions of its Otter spacecraft.
Under an agreement announced Feb. 5, Quindar will provide software to manage and automate operations for Starfish’s initial Otter missions, which are expected to begin launching this year. Financial terms were not disclosed.
Based in Denver, Quindar offers a cloud-hosted platform that allows satellite operators to track spacecraft, send commands and automate routine ground operations. The company positions its software as an alternative to traditional, custom-built mission control systems that operators typically develop in-house and maintain over the life of a program.

Why comparisons between AI and human intelligence miss the point
AI systems, by contrast, do not cooperate, negotiate meaning, form social bonds or engage in shared moral reasoning. They process information in isolation, responding to prompts without awareness, intention or accountability.
Embodiment and social understanding matter
Human intelligence is also embodied. Our thinking is shaped by physical experience, emotion and social interaction. Developmental psychology shows that learning begins in infancy through touch, movement, imitation and shared attention with others. These embodied experiences ground abstract reasoning later in life.