Microsoft announced an updated version of its Bing search engine using a more advanced version of the tech behind ChatGPT.

Head to https://squarespace.com/eventhorizon to save 10% off your first purchase of a website or domain using code eventhorizon.
Did We Find Them? 8 Candidate Alien Signals Found with a new AI Algorithm by SETI.
A deep-learning search for technosignatures of 820 nearby stars.
https://seti.berkeley.edu/ml_gbt/MLSETI_NatAstron_arxiv3.pdf.
YouTube Membership: https://www.youtube.com/channel/UCz3qvETKooktNgCvvheuQDw/join.
Podcast: https://anchor.fm/john-michael-godier/subscribe.
Apple: https://apple.co/3CS7rjT
More JMG
https://www.youtube.com/c/JohnMichaelGodier.
Want to support the channel?
Patreon: https://www.patreon.com/EventHorizonShow.
Follow us at other places!
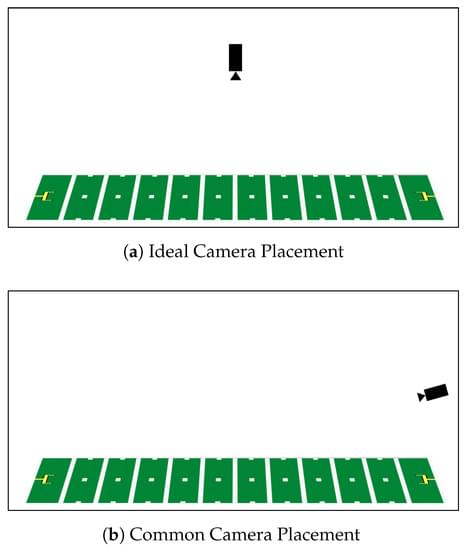
Annotation and analysis of sports videos is a time-consuming task that, once automated, will provide benefits to coaches, players, and spectators. American football, as the most watched sport in the United States, could especially benefit from this automation. Manual annotation and analysis of recorded videos of American football games is an inefficient and tedious process. Currently, most college football programs focus on annotating offensive formations to help them develop game plans for their upcoming games. As a first step to further research for this unique application, we use computer vision and deep learning to analyze an overhead image of a football play immediately before the play begins. This analysis consists of locating individual football players and labeling their position or roles, as well as identifying the formation of the offensive team.

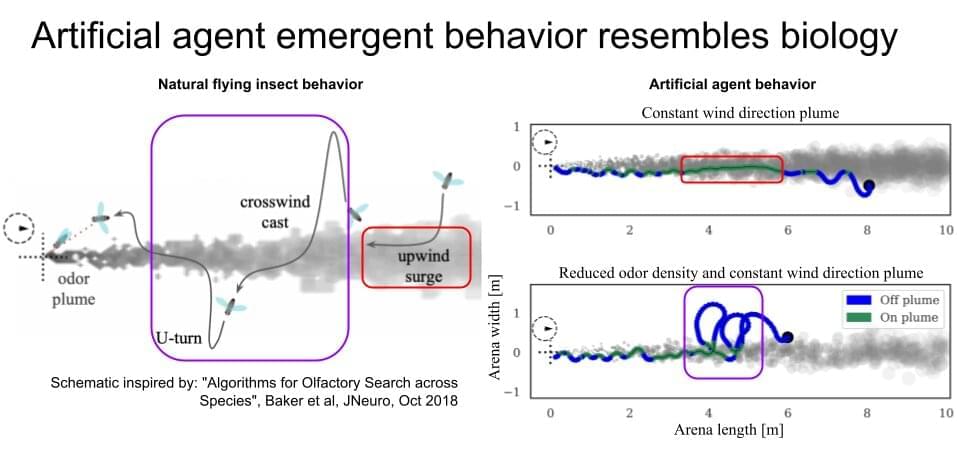
For a long time, scientists and engineers have drawn inspiration from the amazing abilities of animals and have sought to reverse engineer or reproduce these in robots and artificial intelligence (AI) agents. One of these behaviors is odor plume tracking, which is the ability of some animals, particularly insects, to home in on the source of specific odors of interest (e.g., food or mates), often over long distances.
A new study by researchers at University of Washington and University of Nevada, Reno has taken an innovative approach using artificial neural networks (ANNs) in understanding this remarkable ability of flying insects. Their work, recently published in Nature Machine Intelligence, exemplifies how artificial intelligence is driving groundbreaking new scientific insights.
“We were motivated to study a complex biological behavior, odor plume-tracking, that flying insects (and other animals) use to find food or mates,” Satpreet H. Singh, the lead author on the study, told Tech Xplore. “Biologists have experimentally studied many aspects of insect plume tracking in great detail, as it is a critical behavior for insect survival and reproduction. ”.


Deepfake technology has been around for some time, and it’s currently causing controversies for the potential threats it may bring when fallen into the wrong hands. Even India’s business tycoon Anand Mahindra sparked alarm over hyper-realistic synthetic videos.
But some personalities are redefining the way viewers perceive deepfakes. For instance, David Guetta recently synthesized Eminem’s voice to hype up an event. And it’s only one of the many examples of people using artificial intelligence (AI) for entertainment. In fact, it already came to different social media websites like Twitch that take streaming to the next level.
Bachir Boumaaza is a Youtuber who once made a name for his record-breaking games, which he used to help numerous charities. But he became inactive, with most of his fans wondering where he went, thinking it might’ve been the end of his career.
Gleams Akihabara 703 2−8−16 Higashi-Kanda Chiyoda-ku Tokyo 101‑0031 Japan.
Tel: +81 3 5829 5,900 Fax: +81 3 5829 5,919 Email: [email protected]
©2023 GPlusMedia Inc.
CarMax already uses this automated vehicle inspection system.
UVeye’s technology is reducing fatalities out on the road by harnessing the power of AI and high-definition cameras to detect faulty tires, fluid leaks and damaged components before a possible accident or breakdown.

The first time a language model was used to synthesize human proteins.
Of late, AI models are really flexing their muscles. We have recently seen how ChatGPT has become a poster child for platforms that comprehend human languages. Now a team of researchers has tested a language model to create amino acid sequences, showcasing abilities to replicate human biology and evolution.
The language model, which is named ProGen, is capable of generating protein sequences with a certain degree of control. The result was achieved by training the model to learn the composition of proteins. The experiment marks the first time a language model was used to synthesize human proteins.
A study regarding the research was published in the journal *Nature Biotechnology Thursday. *The project was a combined effort from researchers at the University of California-San Francisco and the University of California-Berkeley and Salesforce Research, which is a science arm of a software company based in San Fransisco.
## The significance of using a language model
Researchers say that a language model was used for its ability to generate protein sequences with a predictable function across large protein families, akin to generating grammatically and semantically correct natural language sentences on diverse topics.
“In the same way that words are strung together one-by-one to form text sentences, amino acids are strung together one-by-one to make proteins,” Nikhil Naik, the Director of AI Research at Salesforce Research, told *Motherboard*. The team applied “neural language modeling to proteins for generating realistic, yet novel protein sequences.”