Human intelligence may be just a brief phase before machines take over. That may answer where the aliens are hiding.

Summary: Researchers developed a machine learning algorithm, FoodProX, capable of predicting the degree of processing in food products.
The tool scores foods on a scale from zero (minimally or unprocessed) to 100 (highly ultra-processed). FoodProX bridges gaps in existing nutrient databases, providing higher resolution analysis of processed foods.
This development is a significant advancement for researchers examining the health impacts of processed foods.

The system demonstrated its chops on Kepler’s third law of planetary motion, Einstein’s relativistic time-dilation law, and Langmuir’s equation of gas adsorption.
AI-Descartes, a new AI scientist, has successfully reproduced Nobel Prize-winning work using logical reasoning and symbolic regression to find accurate equations. The system is effective with real-world data and small datasets, with future goals including automating the construction of background theories.
In 1918, the American chemist Irving Langmuir published a paper examining the behavior of gas molecules sticking to a solid surface. Guided by the results of careful experiments, as well as his theory that solids offer discrete sites for the gas molecules to fill, he worked out a series of equations that describe how much gas will stick, given the pressure.
Join top executives in San Francisco on July 11–12, to hear how leaders are integrating and optimizing AI investments for success. Learn More
Back on New Year’s Day, I wrote a piece for VentureBeat predicting 2023 as the year of mixed reality. On Monday of next week, the world will see why I still believe this is true. That’s the day Apple is expected to unveil its long-awaited mixed reality headset, a product rumored to be called the “Reality Pro” and certain to set the standard for immersive experiences.
This is a big deal.
It’s time to toss AI onto the big pile of problems that Americans worry about constantly but do nothing to fix.
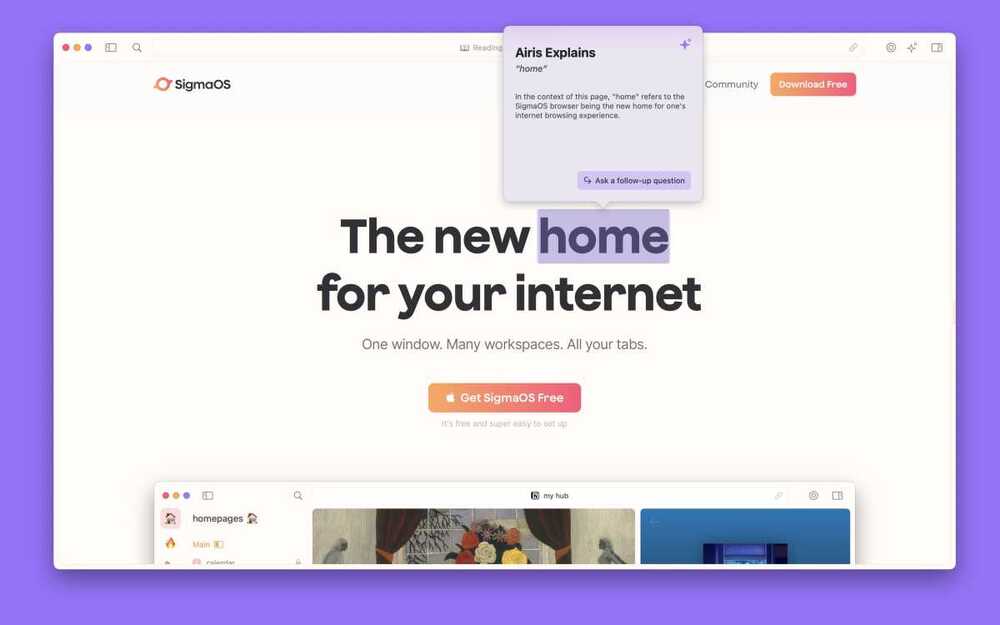
While OpenAI launched an official ChatGPT app for iOS, most of the AI-powered chatbots are still best accessible through the web. And that’s why browsers are stepping up to integrate AI-aided features within their apps. LocalGlobe-and Y Combinator-backed web browser startup SigmaOS launched its own AI assistant on Thursday to a limited set of people.
The company says that the unique thing about Airis, its AI assistant, is that understands a page’s context and gives you answers based on that. Here’s a good example: if you are reading about Manchester United, ask Airis to explain “United” or ask questions about it, the bot understands that you are asking about the football team and not just the word.

Dumme, a startup putting AI to practical use in video editing, is already generating demand before opening up to the public. The Y Combinator-backed company has hundreds of video creators testing its product, which leverages AI to create short-form videos from YouTube content, and a waitlist of over 20,000 pre-launch, it says. Using a combination of both proprietary and existing AI models, Dumme’s promise is that it can not only save on editing time but also — and here’s its big claim — do a better job than the contracted (human) workforce who is often tasked with more menial video editing jobs, like cutting down long-form content for publication on short-form platforms like YouTube Shorts, TikTok or Instagram Reels.
Founded in January 2022 and a participant in startup accelerator Y Combinator’s Winter 2022 program, Dumme co-founder and CEO Merwane Drai said he was originally focused on building a search engine for video. But around six months ago, the team realized that a better product might be to repurpose the same AI models they were developing to edit video clips instead.
Joined by co-founders Will Dahlstrom (CPO) and Jordan Brannan (CTO), all with AI backgrounds, Drai realized Dumme may have landed on the right product-market fit after their app went viral, crashing their servers.
“This tool will eventually enable developers to import detailed objects — whether small statues or massive buildings — into virtual environments for video games or industrial digital twins.”
Artificial intelligence (AI) company and chip manufacturer Nvidia announced the latest AI tool in its army of models.
Neuralangelo is an AI model that turns 2D video clips into detailed 3D structures. It uses neural networks for 3D reconstruction, generating life-like virtual replicas of buildings, sculptures, and other real-world objects.

{kind=link}