We may be on the cusp of an era of astonishing innovation — the limits of which aren’t even clear yet.


The increasing demand for ever-faster information processing has ushered in a new era of research focused on high-speed electronics operating at frequencies nearing terahertz and petahertz regimes. While existing electronic devices predominantly function in the gigahertz range, the forefront of electronics is pushing towards millimeter waves, and the first prototypes of high-speed transistors, hybrid photonic platforms, and terahertz metadevices are starting to bridge the electronic and optical domains.
However, characterizing and diagnosing such devices pose a significant challenge due to the limitations of available diagnostic tools, particularly in terms of speed and spatial resolution. How shall one measure a breakthrough device if it’s the fastest and smallest of its kind?
In response to this challenge, a team of researchers from the University of Konstanz now proposes an innovative solution: They create femtosecond electron pulses in a transmission electron microscope, compress them with infrared laser light to merely 80 femtosecond duration, and synchronize them to the inner fields of a laser-triggered electronic transmission line with the help of a photoconductive switch. Then, using a pump-probe approach, the researchers directly sense the local electromagnetic fields in their electronic devices as a function of space and time.

Researchers at the University of Rochester’s Laboratory for Laser Energetics (LLE) have led experiments showcasing an efficient “spark plug” for direct-drive approaches to inertial confinement fusion (ICF). In a pair of studies featured in Nature Physics, the team shares their findings and details the potential for scaling up these methods, aiming for successful fusion in a future facility.
LLE is the largest university-based U.S. Department of Energy program and hosts the OMEGA laser system, which is the largest academic laser in the world but still almost one hundredth the energy of the National Ignition Facility (NIF) at the Lawrence Livermore National Laboratory in California. With OMEGA, Rochester scientists completed several successful attempts to fire 28 kilojoules of laser energy at small capsules filled with deuterium and tritium fuel, causing the capsules to implode and produce a plasma hot enough to initiate fusion reactions between the fuel nuclei. The experiments caused fusion reactions that produced more energy than the amount of energy in the central hot plasma.
The OMEGA experiments use direct laser illumination of the capsule and differ from the indirect drive approach used on the NIF. When using the indirect drive approach, the laser light is converted into X-rays that in turn drive the capsule implosion. The NIF used indirect drive to irradiate a capsule with X-rays using about 2,000 kilojoules of laser energy. This led to a 2022 breakthrough at NIF in achieving fusion ignition —a fusion reaction that creates a net gain of energy from the target.

The team behind the breakthrough used the Atacama Large Millimeter/ submillimeter Array (ALMA) to zoom in on water vapor locked up in gas and dust within a protoplanetary disk surrounding the sun-like star HL Tauri, located 450 light-years away from Earth in the constellation Taurus.
“I had never imagined that we could capture an image of oceans of water vapor in the same region where a planet is likely forming,” Stefano Facchini research leader and an astronomer at the University of Milan, said in a statement. “Our results show how the presence of water may influence the development of a planetary system, just like it did some 4.5 billion years ago in our own solar system.”


A sodium battery developed by researchers at The University of Texas at Austin significantly reduces fire risks from the technology, while also relying on inexpensive, abundant materials to serve as its building blocks.
Though battery fires are rare, increased battery usage means these incidents are on the rise.
The secret ingredient to this sodium battery breakthrough, published recently in Nature Energy, is a solid diluent. The researchers used a salt-based solid diluent in the electrolyte, facilitating the charge-discharge cycle. A specific type of salt—sodium nitrate—allowed the researchers to deploy just a single, nonflammable solvent in the electrolyte, stabilizing the battery as a whole.
Wonderful work truly breakthrough for different types of compounds for chemistry. Year 2021.
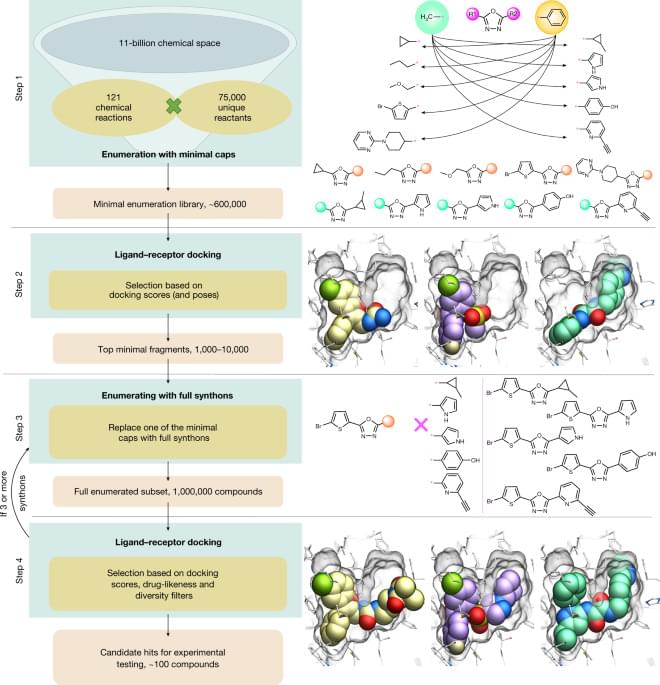
V-SYNTHES, a scalable and computationally cost-effective synthon-based approach to compound screening, identified compounds with a high affinity for CB2 and CB1 in a hierarchical structure-based screen of more than 11 billion compounds.
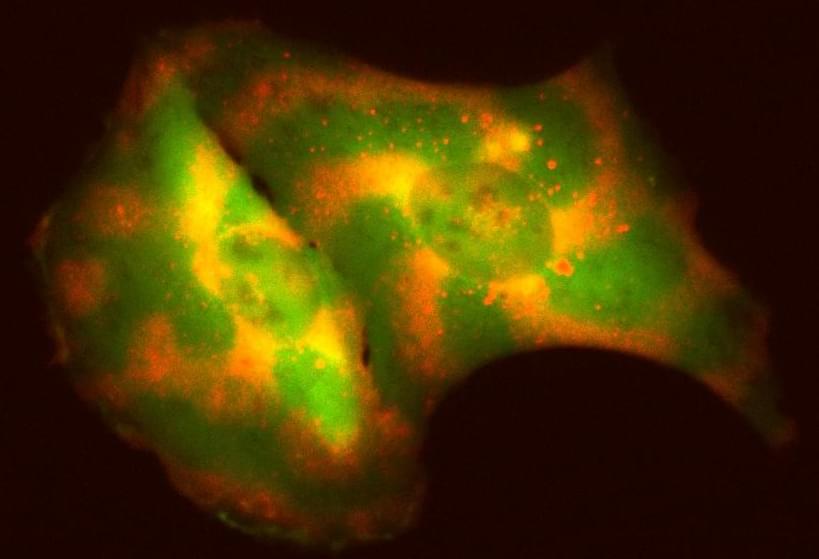
Researchers can engineer cells to express new genes and produce specific proteins, giving the cells new parts to work with. But, it’s much harder to provide cells with instructions on how to organize and use those new parts. Now, new tools from University of Wisconsin–Madison researchers offer an innovative way around this problem.
Their research is published in the journal Cell.
Everything a cell does depends on how molecules are organized within the cell. Inside our cells—all cells—proteins and other molecules undergo organization and reorganization to carry out cellular function. Like a fleet of commuter trains moving at scheduled intervals along their different routes, proteins within a cell are organized in time and space to carry out complex but predictable functions.
Philosopher David Chalmers and neuroscientist Christof Koch made a bet in 1998 on a breakthrough in consciousness research within 25 years. Now the bet is settled – thanks to the journalist Per Snaprud, neuroscience editor at the Swedish popular science magazine Forskning \& Framsteg. Here’s a conversation that was held between the three at New York university on June 24:th 2023.