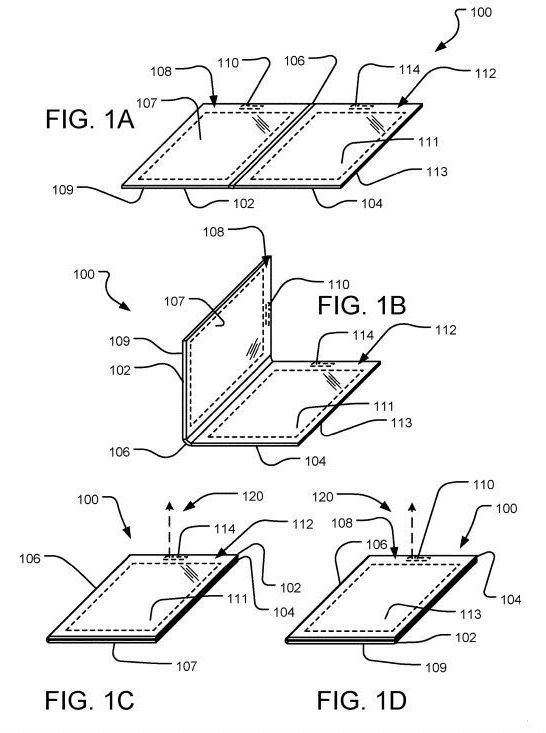
Microsoft’s patent filing recently made public has juiced up curiosity over what Microsoft might debut sooner or later as its own version of a folding computing device.
MSPoweruser took the view that “Microsoft is trying hard to bring its first foldable device to the market, like every other big tech companies.” It’s apparent now that “the Redmond giant has filed yet another patent for its much-awaited foldable Windows 10 device.”
The patent “Multi-Sided Electromagnetic Coil Access Assembly” was filed in February last year but only recently made public. It is particularly drawing interest because, as TechRadar said, what would make this foldable idea work would be “a multi-sided electromagnetic coil for wireless charging.”