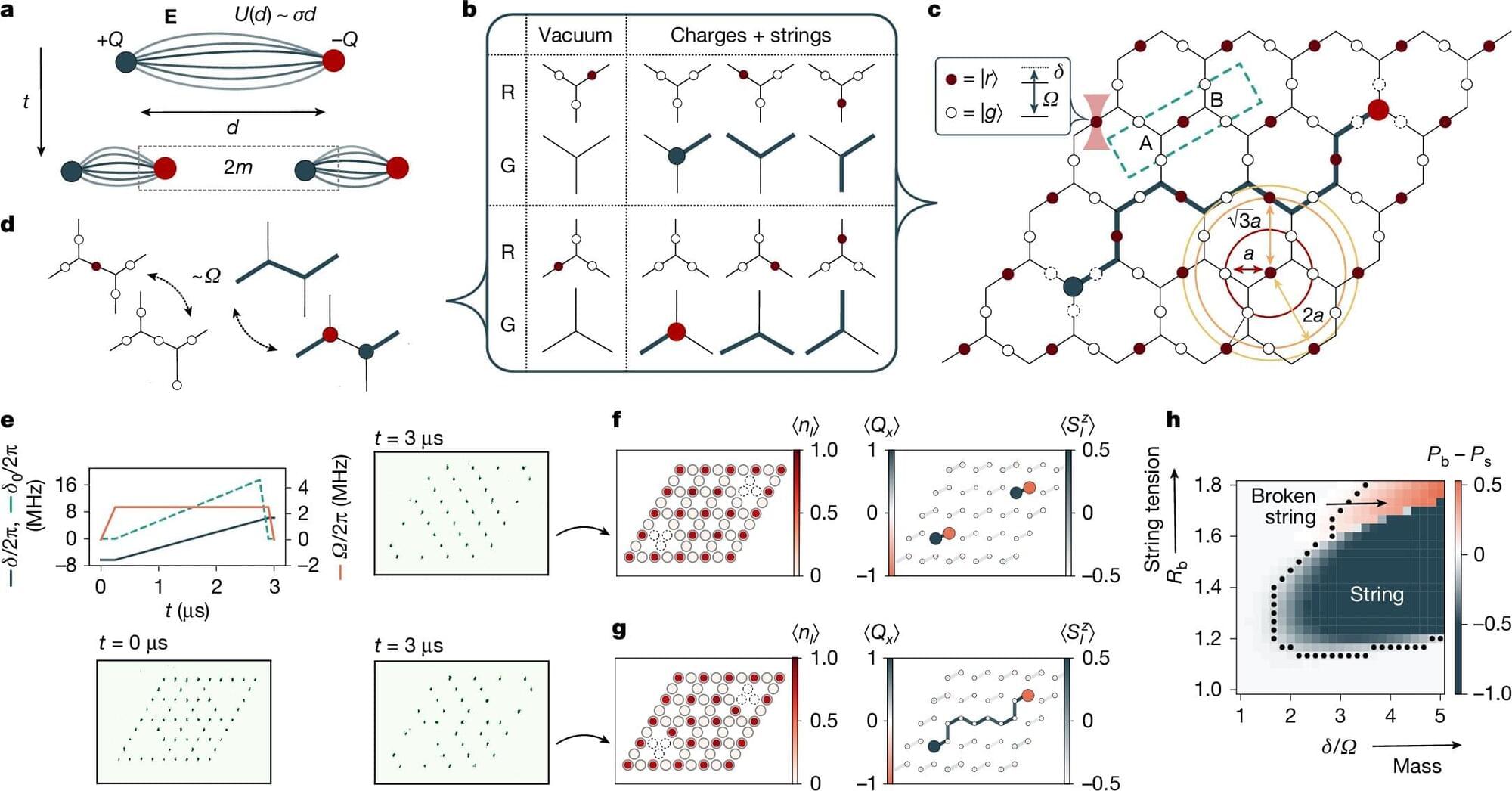
An international team led by Innsbruck quantum physicist Peter Zoller, together with the US company QuEra Computing, has directly observed a gauge field theory similar to models from particle physics in a two-dimensional analog quantum simulator for the first time. The study, published in Nature, opens up new possibilities for research into fundamental physical phenomena.
String breaking occurs when the string between two strongly bound particles, such as a quark-antiquark pair, breaks and new particles are created. This concept is central to understanding the strong interactions that occur in quantum chromodynamics (QCD), the theory that describes the binding of quarks in protons and neutrons.
String breaking is extremely difficult to observe experimentally, as it only occurs in nature under extreme conditions. The recent work by scientists from the Universities of Innsbruck and Harvard, the ÖAW-Institute for Quantum Optics and Quantum Information (IQOQI) and the quantum computer company QuEra shows for the first time how this phenomenon can be reproduced in an analog quantum simulator.




{kind=link}