New therapies that are less intrusive but more lasting than current interventions promise to arrest and even reverse neurodegeneration.

Scientists at The University of Manchester have achieved a significant breakthrough in using cyanobacteria—commonly known as “blue-green algae”—to convert carbon dioxide (CO2) into valuable bio-based materials.
Their work, published in Biotechnology for Biofuels and Bioproducts, could accelerate the development of sustainable alternatives to fossil fuel-derived products like plastics, helping pave the way for a carbon-neutral circular bioeconomy.
The research, led by Dr. Matthew Faulkner, working alongside Dr. Fraser Andrews, and Professor Nigel Scrutton, focused on improving the production of citramalate, a compound that serves as a precursor for renewable plastics such as Perspex or Plexiglas. Using an innovative approach called “design of experiment,” the team achieved a remarkable 23-fold increase in citramalate production by optimizing key process parameters.
Thank you to today’s sponsors:
Eight Sleep: Head to https://impacttheory.co/eightsleepAugust24 and use code IMPACT to get $350 off your Pod 4 Ultra.
Netsuite: Head to https://impacttheory.co/netsuiteAugust24 for Netsuite’s one-of-a-kind flexible financing program for a few more weeks!
Aura: Secure your digital life with proactive protection for your assets, identity, family, and tech – Go to https://aura.com/impacttheory to start your free two-week trial.
Welcome to Impact Theory, I’m Tom Bilyeu and in today’s episode, Nick Bostrom and I dive into the moral and societal implications of AI as it becomes increasingly advanced.
Nick Bostrom is a leading philosopher, author, and expert on AI here to discuss the future of AI, its challenges, and its profound impact on society, meaning, and our pursuit of happiness.
We touch on treating AI with moral consideration, the potential centralization of power, automation of critical sectors like police and military, and the creation of hyper-stimuli that could impact society profoundly.
We also discuss Nick’s book, Deep Utopia, and what the ideal human life will look like in a future dominated by advanced technology, AI, and biotechnology.
Our conversation navigates through pressing questions about AI aligning with human values, the catastrophic consequences of powerful AI systems, and the need for deeper philosophical and ethical considerations as AI continues to evolve.

Summary: A study reveals how brain cell interactions influence aging, showing that rare cell types either accelerate or slow brain aging. Neural stem cells provide a rejuvenating effect on neighboring cells, while T cells drive aging through inflammation. Researchers used advanced AI tools and a spatial single-cell atlas to map cellular interactions across the lifespan in mice.
This work sheds light on how interventions, such as enhancing neural stem cells, might combat neurodegeneration. By understanding these cellular dynamics, scientists can explore tailored therapies to slow aging and promote brain resilience. The findings also offer insights into conditions like Alzheimer’s disease, highlighting the importance of cell-to-cell interactions.
Cellular research indicates that neuropilin-1 plays a crucial role in pain signaling, presenting a potential pathway for developing or repurposing treatments to manage chronic pain.
Researchers at the NYU Pain Research Center have identified a novel receptor for nerve growth factor (NGF) that plays a critical role in pain signaling, despite being unable to signal independently. These findings, published in the Journal of Clinical Investigation, could pave the way for new treatments for arthritis, inflammatory pain, and cancer pain—addressing the limitations of previous therapies that failed in clinical trials due to side effects.
“Nerve growth factor is unusual because it’s one of the few patient-validated targets for pain,” said Nigel Bunnett, professor and chair of the Department of Molecular Pathobiology at NYU College of Dentistry and the study’s senior author. “We wanted to think of a way of circumventing side effects in an effort to find safer, non-opioid therapies for arthritis and other forms of chronic pain.”
A new review by researchers from Oxford Population Health and the University of Iceland, published in Nature Aging, reveals how your DNA shapes reproductive health, fertility, and even life expectancy.
Led by researchers from the University of Oxford’s Leverhulme Centre for Demographic Science and the University of Iceland, the review explores how genetic variations can explain differences in reproductive health and longevity.
The study provides the most comprehensive review of male and female genetic discoveries of reproductive traits to date, and provides new insights into how our DNA affects when we have children, the timing of menopause, and even how that is connected to how long we live.
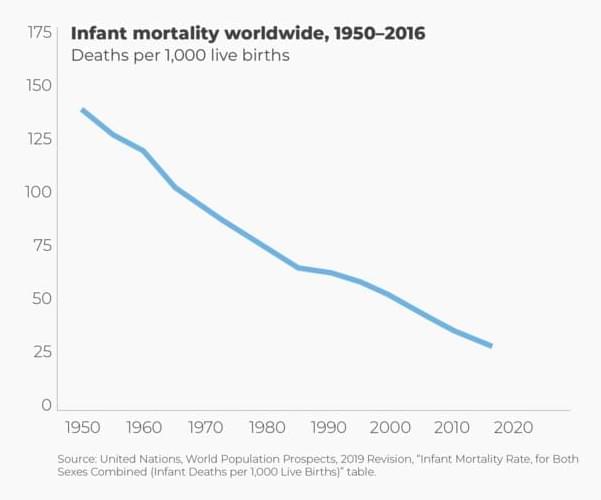
Demographers estimate that in premodern societies, out of every 1,000 babies born, about 300 died before reaching their first birthday. Most of those infants succumbed to infectious diseases and malnutrition.
By 1900, infant mortality rates had fallen to approximately 140 per 1,000 live births in modernizing countries, such as the United Kingdom and the United States. Infant mortality rates in the two countries continued to fall to about 56 per 1,000 live births in 1935 and down to about 30 per 1,000 live births by 1950. In 2017, the UK and U.S. infant mortality rates were, respectively, 3.8 and 5.9 per 1,000 live births. Since 1900, in other words, infant mortality in those two countries has fallen by more than 95 percent.
In the past few decades, infant mortality rates have been falling steeply in the rest of the world. The World Health Organization estimates that the global infant mortality rate was just under 160 per 1,000 live births in 1950. By 1990, the agency reports that the global infant mortality rate had dropped to 64.8 per 1,000 live births. In 2017, the global infant mortality rate was down to 29.4 per 1,000 live births, about the level of the United Kingdom and the United States in 1950.
There are various studies that have explored the role of the body’s circadian rhythm in regulating immune activity. Disruptions in the circadian rhythms exacerbate inflammation. Researchers from the Royal College of Surgeons in Ireland (RCSI) University of Medicine and Health Sciences have previously studied how the immune cells called macrophages are affected without an internal body clock. Now, new research by RCSI describes how macrophages work differently at various times of day and could pave the way for time-targeted treatments for inflammatory diseases. The research also illuminates a key role for mitochondria in driving daily changes in immune activity.
The findings are published in The FASEB Journal in an article titled, “Time-of-day control of mitochondria regulates NLRP3 inflammasome activation in macrophages.”
Macrophages release interleukin-1 (IL-1) cytokines in response to inflammatory stimuli, and the NLRP3 inflammasome mediates IL-1-family cytokine release via pyroptosis. Mitochondria play a multifaceted role regulating NLRP3 inflammasome activity. However, whether the macrophage clock regulates the NLRP3 inflammasome via mitochondrial control remains unclear.

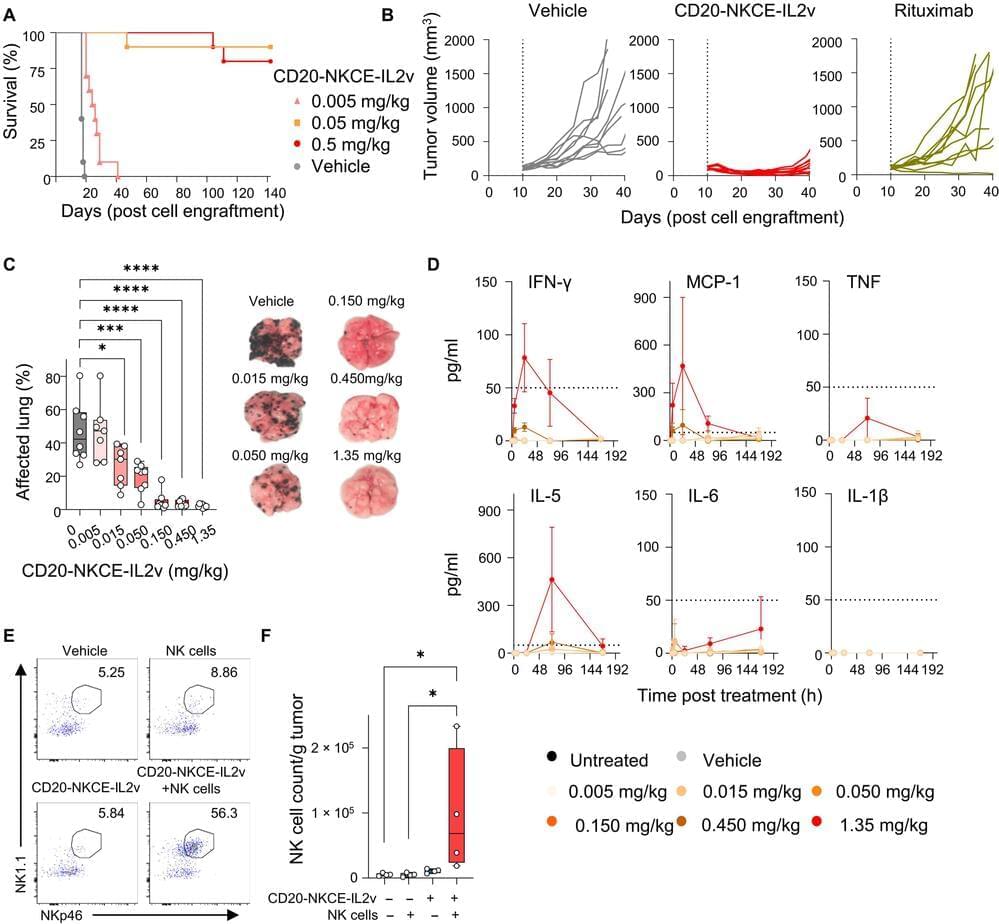
An investigational therapy is demonstrating preclinical promise against non-Hodgkin lymphoma by boosting natural killer cells and efficiently annihilating the malignancy without toxicity to the patient, a team of cancer biologists in France has found.
The emerging therapy is for B cell non-Hodgkin lymphoma, the most common form of lymphoma worldwide. Current therapies target the CD20+ protein on the surface of cancerous B cells but with limited efficacy. A newly developed antibody-based molecule targets B-non-Hodgkin lymphoma by engaging natural killer cells, warriors of the immune system. The experimental therapeutic is expected to help patients whose disease rebounds and is difficult to treat.
“Non-Hodgkin lymphoma is the most frequent hematological malignancy in humans, comprising nearly 3% of all cancer diagnoses and oncology-related mortalities,” writes Dr. Olivier Demaria, lead author of the research published in Science Immunology.