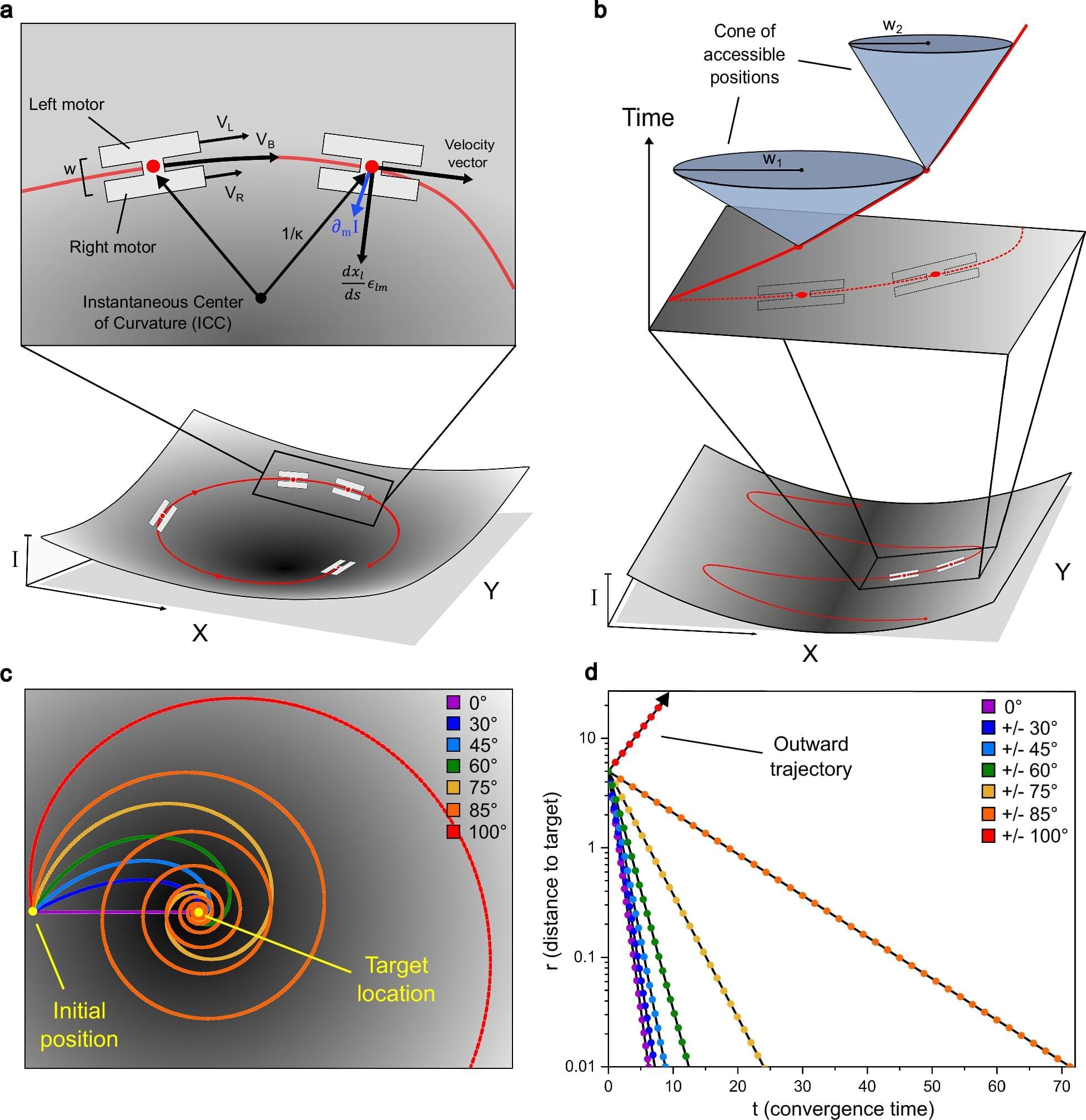
Microrobots—tiny robots less than a millimeter in size—are useful in a variety of applications that require tasks to be completed at scales far too small for other tools, such as targeted drug-delivery or micro-manufacturing. However, the researchers and engineers designing these robots have run into some limitations when it comes to navigation. A new study, published in Nature, details a novel solution to these limitations—and the results are promising.
The biggest problem when dealing with microrobots is the lack of space. Their tiny size limits the use of components needed for onboard computation, sensing and actuation, making traditional control methods hard to implement. As a result, microrobots can’t be as “smart” as their larger cousins.
Researchers have tried to cover this limitation already. In particular, two methods have been studied. One method of microrobot control uses external feedback from an auxiliary system, usually with something like optical tweezers or electromagnetic fields. This has yielded precise and adaptable control of small numbers of microrobots, beneficial for complex, multi-step tasks or those requiring high accuracy, but scaling the method for controlling large numbers of independent microrobots has been less successful.