Governments look at banning ransom payments in face of increasingly sophisticated threats.

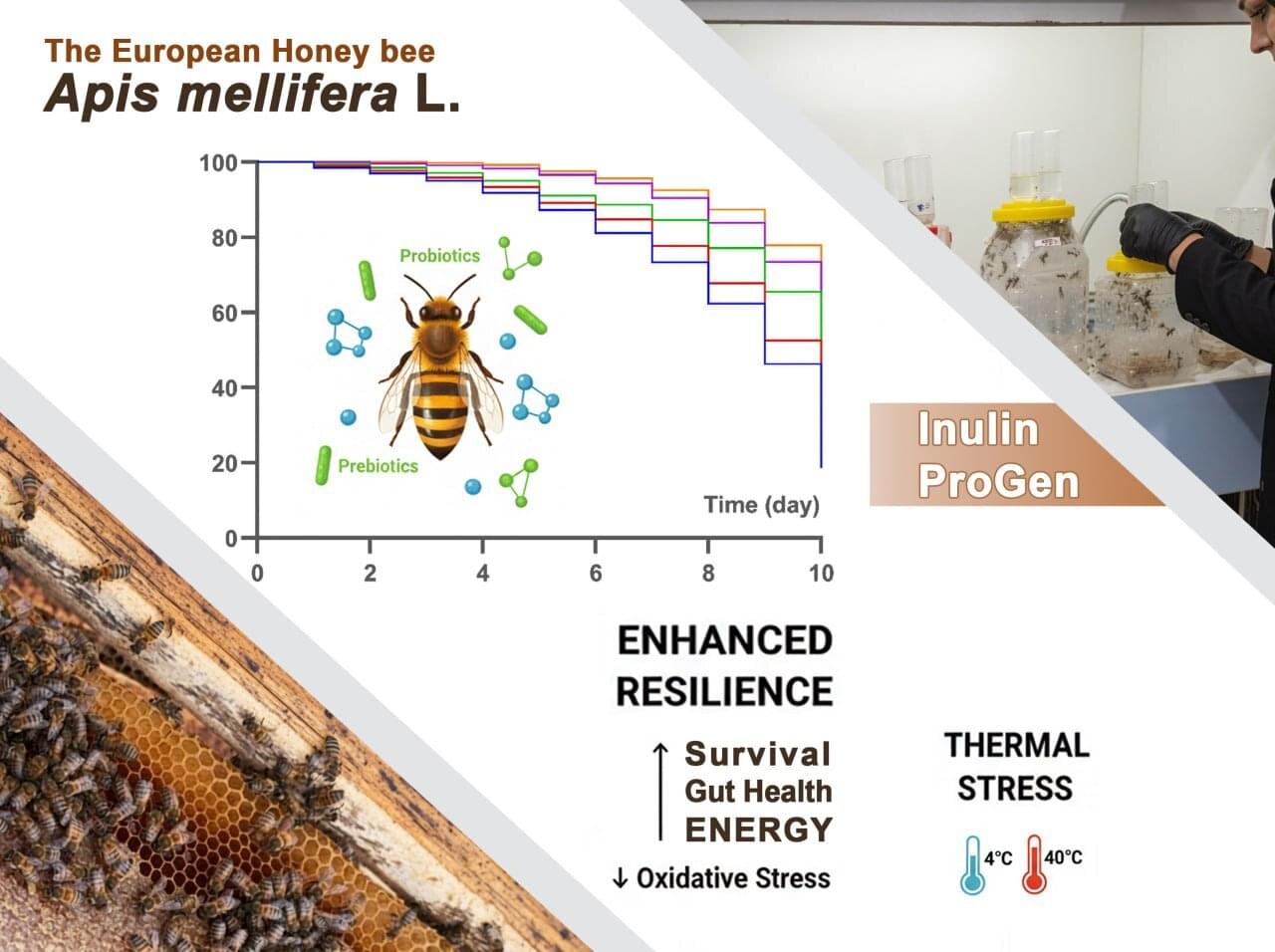
Honeybees do not like cold weather. When temperatures dip, they can become sluggish and unable to fly. But no matter the conditions in the outside world, they try to keep their hives close to a comfortable 34°C–36°C (93°F–97°F). However, extreme weather, both hot and cold, can overwhelm this internal temperature control and ultimately cut their lives short.
That may not be a problem, though, if they are given a dietary boost. Researchers led by Dr. Najmeh Sahebzadeh at the University of Zabol in southeastern Iran wondered whether feeding them a diet containing a probiotic (live beneficial bacteria) and a prebiotic (fiber that feeds those bacteria) could enhance their survival.
The results, published in a paper in the journal PLOS One, suggest that it could.
Gelonghui, July 13 | According to Science and Technology Daily, the surge in AI technology has driven strong demand for advanced chips, yet global chip supply remains constrained by the technology and production capacity of only a few companies. In a recent report, Forbes.com noted that as emerging technologies continue to rise, the global approach to manufacturing cutting-edge chips is expected to undergo a major transformation by 2030. Although extreme ultraviolet (EUV) lithography is currently dominant, it is not the only method for ‘drawing’ microscopic transistors onto silicon wafers. A new generation of forward-looking lithography technologies is poised to emerge, potentially replacing EUV lithography and reshaping how advanced chips are manufactured. Atomic lithography abandons ‘light’ and instead

Climate models have long warned that global warming could weaken “deep-water formation”—the density-driven sinking that is the engine of the AMOC. The logic is straightforward: As Greenland’s ice sheets melt and sea ice formation declines, North Atlantic waters will freshen. Combined with warmer sea temperatures, the freshening makes surface waters more buoyant. The AMOC was thought to have shut down abruptly during past climate warmings, and a handful of researchers now argue such a tipping point could occur this century. A sputtering AMOC could trigger a sharp cooldown in northwestern Europe, rising seas along the U.S. east coast, and shifts in tropical rainfall. “It is a risk that would really have severe impacts,” says Stefan Rahmstorf, a climate scientist at Potsdam University and a prominent voice warning of the threat.
Yet for all the alarming headlines, most climate researchers think the AMOC is more resilient than these worst case scenarios make it seem. Emerging evidence suggests the AMOC may not have actually collapsed in the warm climates following ice ages. More detailed climate models suggest it could weaken but not collapse in the current surge of warming. And studies of the AMOC’s present behavior do not yet show any clear signs of trouble. They’re also exposing new facets of the circulation that could buffer any eventual weakening.
“The paradigm has been, if we warm and freshen these areas, we’ll get less dense water and AMOC will slow down,” says Susan Lozier, an oceanographer at the Georgia Institute of Technology. “That paradigm isn’t holding up.”


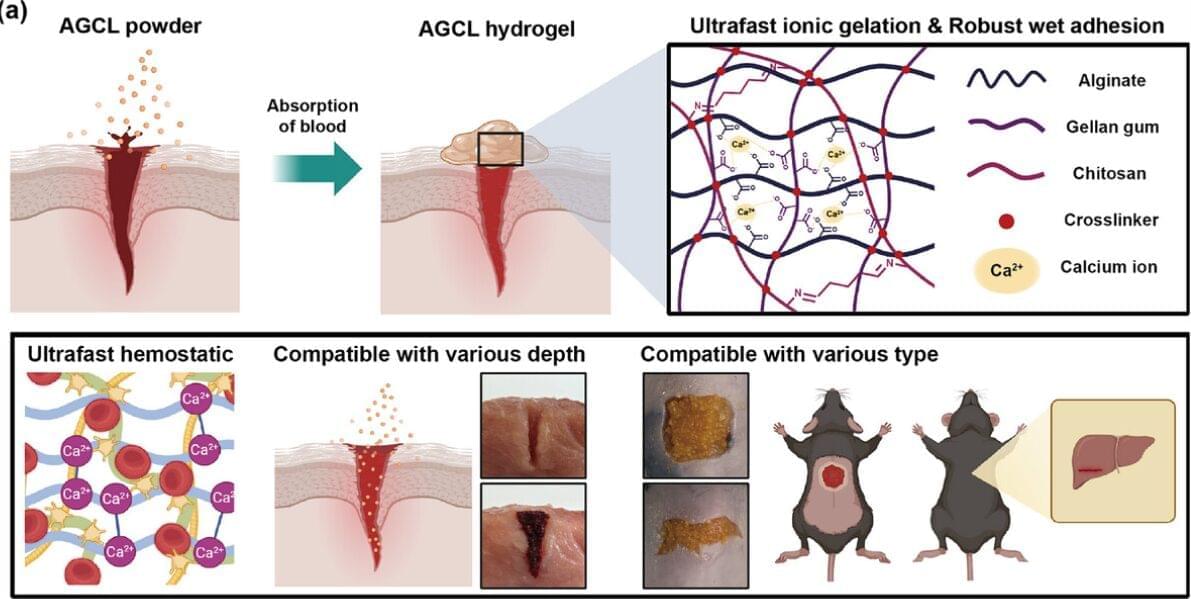
Excessive blood loss is the leading cause of death from combat injuries, making rapid bleeding control one of the biggest challenges in battlefield medicine. Researchers at KAIST, including an Army Major, have developed a next generation spray-on powder that can stop severe bleeding in about one second. The innovation could significantly improve survival for wounded soldiers while also offering broad potential for civilian emergency care.
The research team, led by Professor Steve Park of KAIST’s Department of Materials Science and Engineering and Professor Sangyong Jon of the Department of Biological Sciences, created a powder type hemostatic agent that quickly transforms into a strong hydrogel barrier when sprayed onto a wound.
Because an Army Major directly participated in the project, the technology was designed with real battlefield conditions in mind. The powder hardens almost instantly, remains stable during storage, and can be deployed quickly even in demanding environments such as combat zones and disaster areas.

Researchers at EMBL Hamburg and collaborators at the Leibniz Research Institute for Molecular Pharmacology (FMP) have mapped how the influenza A virus rewires infected human cells in unprecedented detail. To do this, the researchers used a customized experimental workflow to directly observe how proteins interact inside intact infected cells.
Every year, seasonal influenza kills up to 650,000 people globally and causes serious illness for 3–5 million individuals. The influenza A virus, in particular, has been responsible for several pandemics, including the 1918 Spanish flu pandemic. When this virus infects cells, it releases its genetic material, called RNA, which contains blueprints for a handful of proteins. These proteins then spread throughout the host cell and repurpose its molecular machinery to make more viruses.
Scientists want to understand this process in detail because it would help in designing better drug therapies and vaccines against the flu virus. That’s why it’s crucial to figure out how proteins of the flu virus interact with proteins of host cells and subvert them to meet the virus’s needs. This is the first time scientists have mapped direct virus-host protein contacts at scale inside intact influenza-infected cells, with enough structural detail to model how the proteins fit together.
{kind=link}