This research is the first rigorous academic demonstration of goal-directed learning in lab-grown brain organoids, and lays the foundation for adaptive organoid computation—exploring the capacity of lab-grown brain organoids to learn and solve tasks.
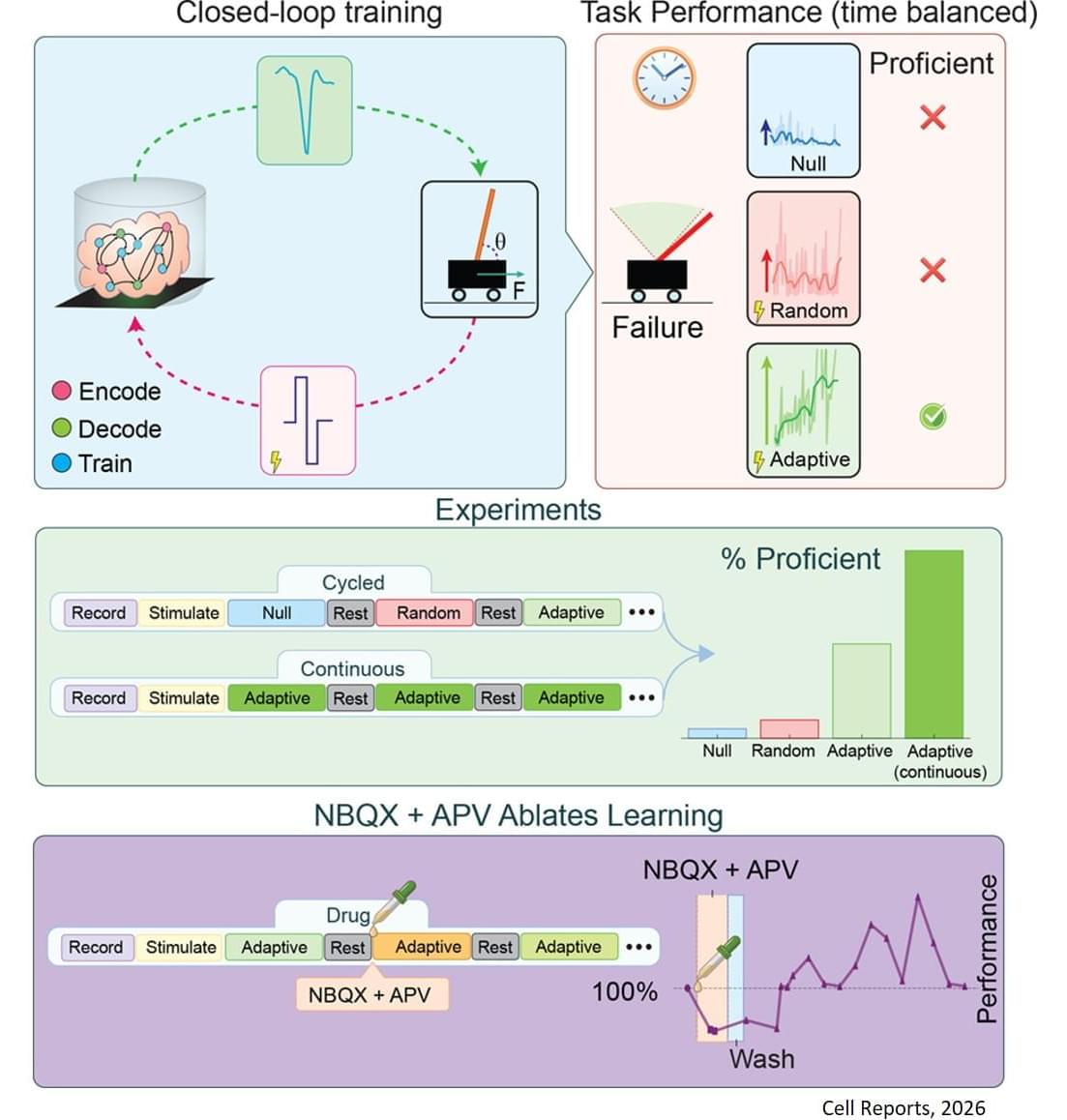
Using organoids derived from mouse stem cells and an electrophysiology system developed by industry partners Maxwell Biosciences, the researchers use electrical simulation to send and receive information to and from neurons. By using stronger or weaker signals, they communicate to the organoid the angle of the pole, which exists in a virtual environment, as it falls in one direction or the other. As this happens, the researchers observe as the organoid sends back signals of how to apply force to balance the pole, and they apply this force to the virtual pole.
For their pole-balancing experiments, the researchers observe as the organoid controls the pole until it drops, which is called an episode. Then, the pole is reset and a new episode begins. In essence, the organoid plays a video game in which the goal is to balance the pole upright for as long as possible.
The researchers observe the organoid’s progress in five-episode increments. If the organoid keeps the pole upright for longer on average in the past five episodes as compared to the past 20, it receives no training signal since it has been improving. If it does not improve the average time it keeps the pole upright, it receives a training signal.
Training feedback is not given to the organoid while it is balancing the pole—only at the end of an episode. An AI algorithm called reinforcement learning is used to select which neurons within the organoid get the training signal.
The results of this study prove that the reinforcement learning algorithm can guide the brain organoids toward improved performance at the cart-pole task—meaning organoids can learn to balance the pole for longer periods of time.
The researchers adopted a rigorous framework for success to make sure they were observing true improvement, and not just random success, including a threshold for the minimum time an organoid needs to balance the pole to “win” the game.
They found that using their coaching technique led to significantly better performance than organoids coached at random, from just a 4.5% “winning” rate for random training, to a 46% winning rate for adaptive training with reinforcement learning.
However, the organoids seem to “forget” most of what they learn during long periods of inactivity. After balancing the pole over many episodes for 15 minutes, the organoid rests for 45 minutes. The researchers found that after this rest period, the organoid’s performance drops back to baseline, indicating it is not retaining its training.
The researchers are interested in further exploring why their coaching technique works—which neurons are best to target, which training signals might work best, and how long-term learning may arise.
To enable this, the author developed an open-source software tool to complement these experiments, called BrainDance. The technology is designed for anyone with the biological skills to culture brain organoids to be able to conduct neural simulation learning experiments and analyze results, without needing to code a game, hardware interface, or training environment themselves—with the goal to enable more people to participate in organoid research and accelerate the field. ScienceMission sciencenewshighlights.
Imagine balancing a ruler vertically in the palm of your hand: you have to constantly pay attention to the angle of the ruler and make many small adjustments to make sure it doesn’t fall over. It takes practice to get good at this.
In engineering, this is called the “inverted pendulum” or “cart-pole” problem, in which a control system learns to balance an upright pole hinged to a moveable cart. This problem is used as a benchmark in fields like robotics, control theory, and artificial intelligence to gauge if a control system can adaptively process and respond to information in a useful way. It’s relevant even in our earliest days—every human infant needs to solve a problem just like this in order to become a toddler.
Researchers trained brain organoids, tiny pieces of brain tissue grown in the lab, to solve this fundamental benchmark problem. By using electrical signals to send and receive information from the organoids, the researcher’s software coached the lab-grown brain tissue to significantly improve its performance at the cart-pole problem.