Fine-tuning large language models via reinforcement learning is computationally expensive, but researchers found a way to streamline the process.
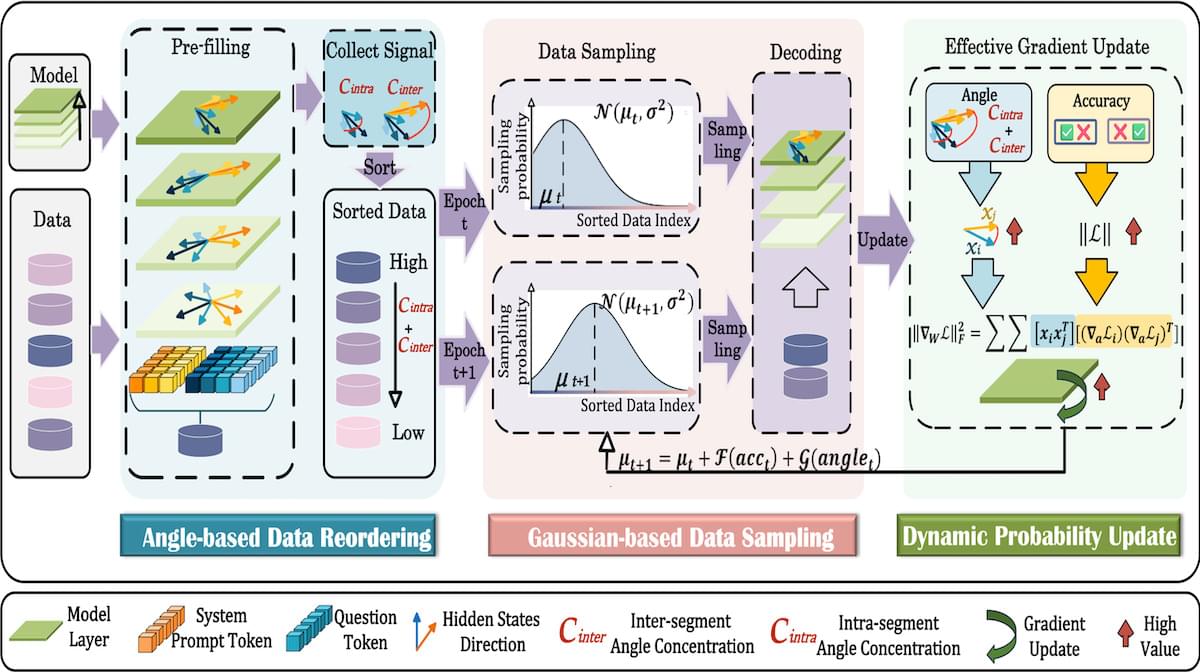
What’s new: Qinsi Wang and colleagues at UC Berkeley and Duke University developed GAIN-RL, a method that accelerates reinforcement learning fine-tuning by selecting training examples automatically based on the model’s own internal signals, specifically the angles between vector representations of tokens. The code is available on GitHub.
Key insight: The cosine similarity between a model’s vector representations of input tokens governs the magnitude of gradient updates during training. Specifically, the sum of those similarities that enter a model’s classification layer, called the angle concentration, governs the magnitude of gradient updates. Examples with higher angle concentration produce larger gradient updates. The magnitude of a gradient update in turn determines the effectiveness of a given training example: The larger the update, the more the model learns. Prioritizing the most-effective examples before transitioning to less-effective ones enhances training efficiency while adding little preprocessing overhead.