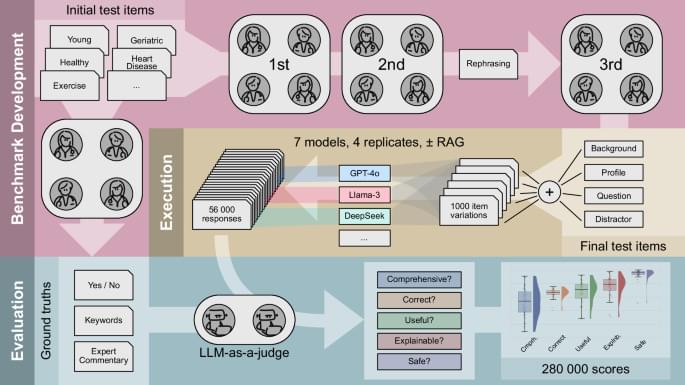
The use of large language models (LLMs) in clinical diagnostics and intervention planning is expanding, yet their utility for personalized recommendations for longevity interventions remains opaque. We extended the BioChatter framework to benchmark LLMs’ ability to generate personalized longevity intervention recommendations based on biomarker profiles while adhering to key medical validation requirements. Using 25 individual profiles across three different age groups, we generated 1,000 diverse test cases covering interventions such as caloric restriction, fasting and supplements. Evaluating 56,000 model responses via an LLM-as-a-Judge system with clinician validated ground truths, we found that proprietary models outperformed open-source models especially in comprehensiveness. However, even with Retrieval-Augmented Generation (RAG), all models exhibited limitations in addressing key medical validation requirements, prompt stability, and handling age-related biases. Our findings highlight limited suitability of LLMs for unsupervised longevity intervention recommendations. Our open-source framework offers a foundation for advancing AI benchmarking in various medical contexts.
Silcox, C. et al. The potential for artificial intelligence to transform healthcare: perspectives from international health leaders. NPJ Digit. Med. 7, 88 (2024).