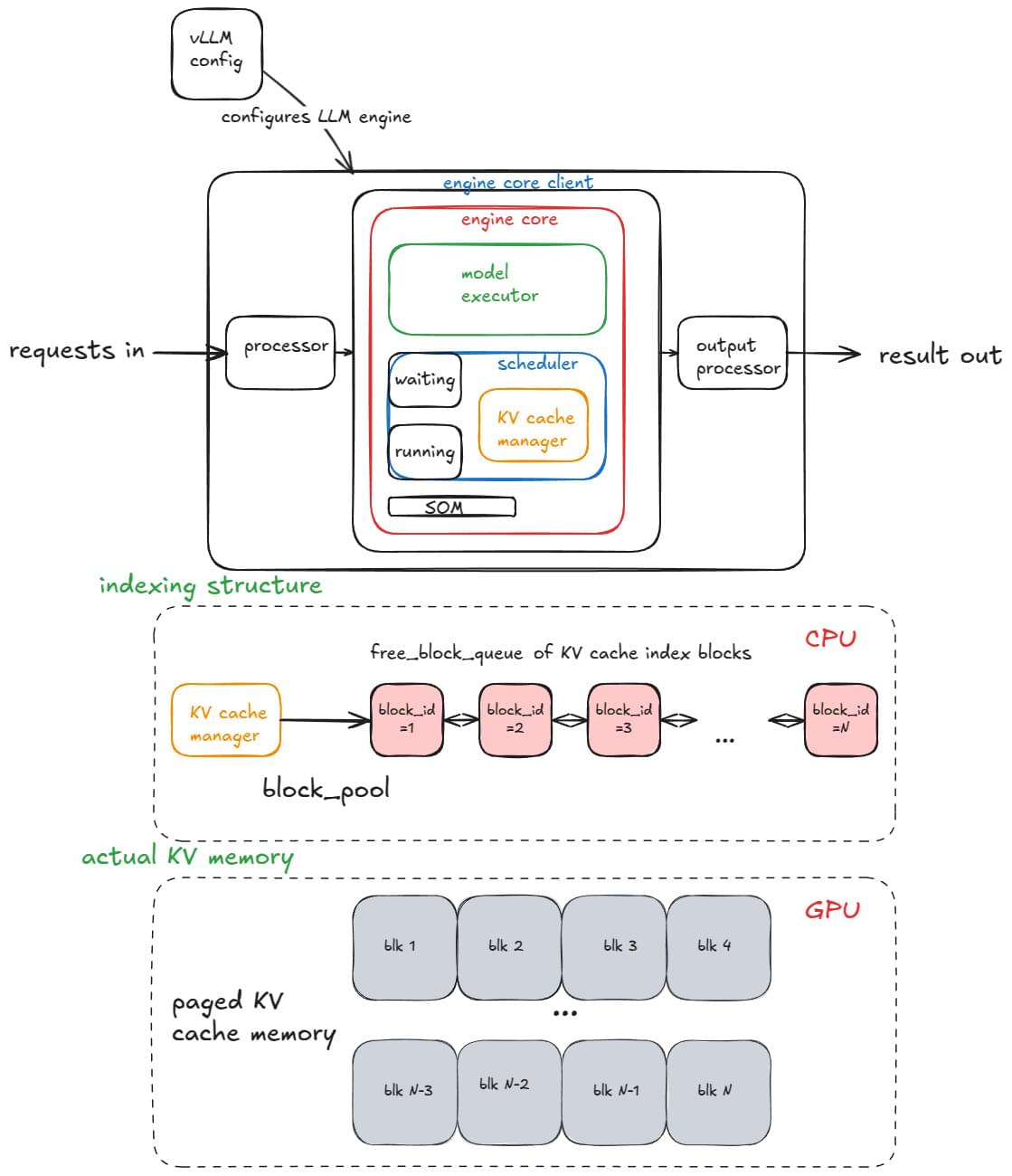
Sep 42025 Inside vLLM: Anatomy of a High-Throughput LLM Inference System From paged attention, continuous batching, prefix caching, specdec, etc. to multi-GPU, multi-node dynamic serving at scale.