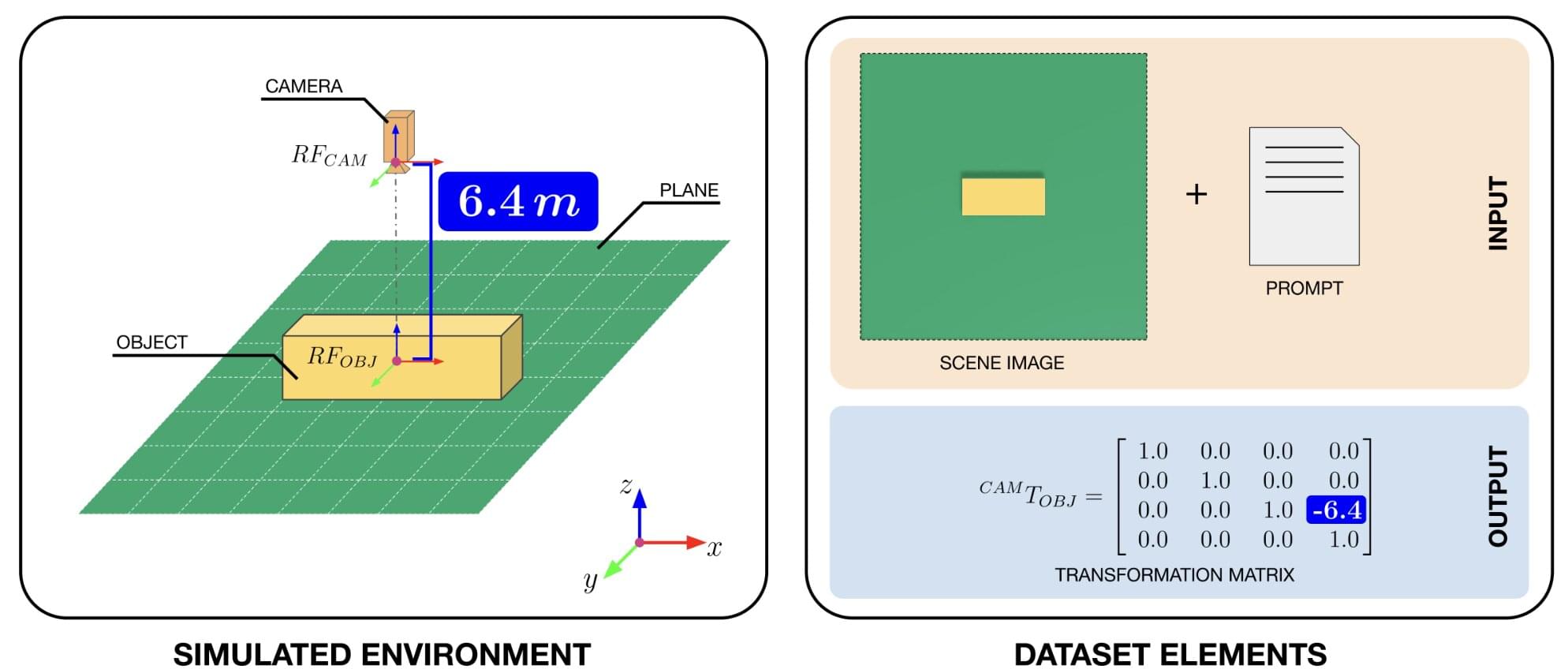
Vision-language models (VLMs) are advanced computational techniques designed to process both images and written texts, making predictions accordingly. Among other things, these models could be used to improve the capabilities of robots, helping them to accurately interpret their surroundings and interact with human users more effectively.