It is widely recognized that continuously scaling both data size and model size can lead to significant improvements in model intelligence. However, the research and industry community has limited experience in effectively scaling extremely large models, whether they are dense or Mixture-of-Expert (MoE) models. Many critical details regarding this scaling process were only disclosed with the recent release of DeepSeek V3. Concurrently, we are developing, a large-scale MoE model that has been pretrained on over 20 trillion tokens and further post-trained with curated Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) methodologies. Today, we are excited to share the performance results of and announce the availability of its API through Alibaba Cloud. We also invite you to explore on Qwen Chat!
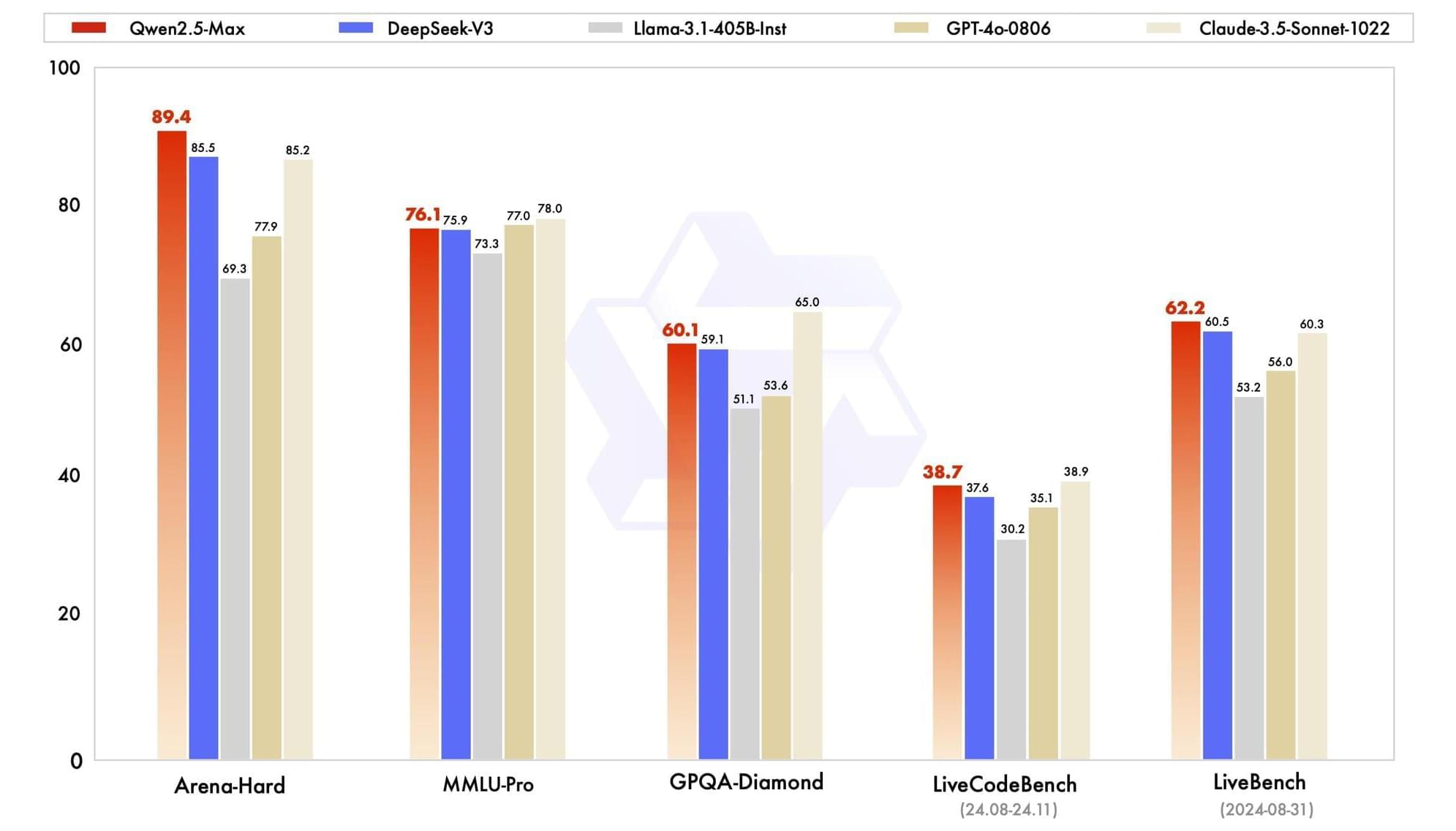
We evaluate alongside leading models, whether proprietary or open-weight, across a range of benchmarks that are of significant interest to the community. These include MMLU-Pro, which tests knowledge through college-level problems, LiveCodeBench, which assesses coding capabilities, LiveBench, which comprehensively tests the general capabilities, and Arena-Hard, which approximates human preferences. Our findings include the performance scores for both base models and instruct models.