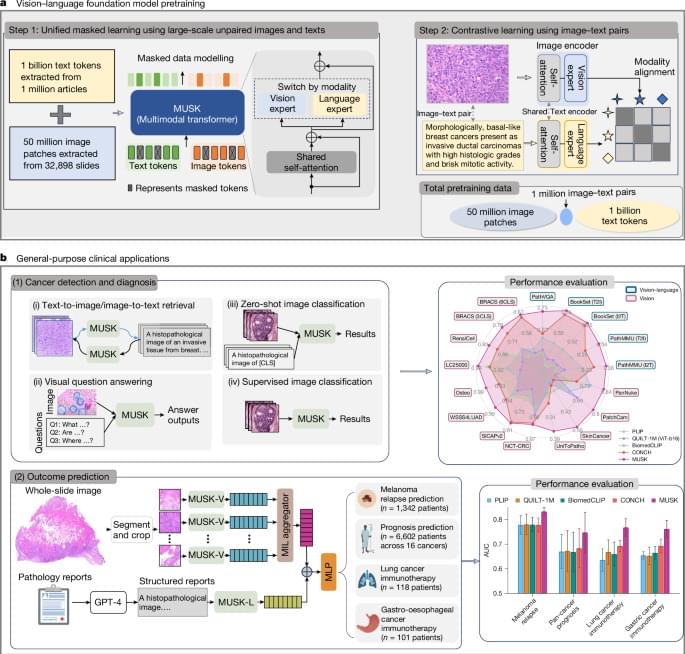
Trained on unlabelled, unpaired image and text data, the Multimodal transformer with Unified maSKed modeling excelled in outcome prediction, image-to-text retrieval and visual question answering, potentially improving cancer diagnosis and therapy precision.