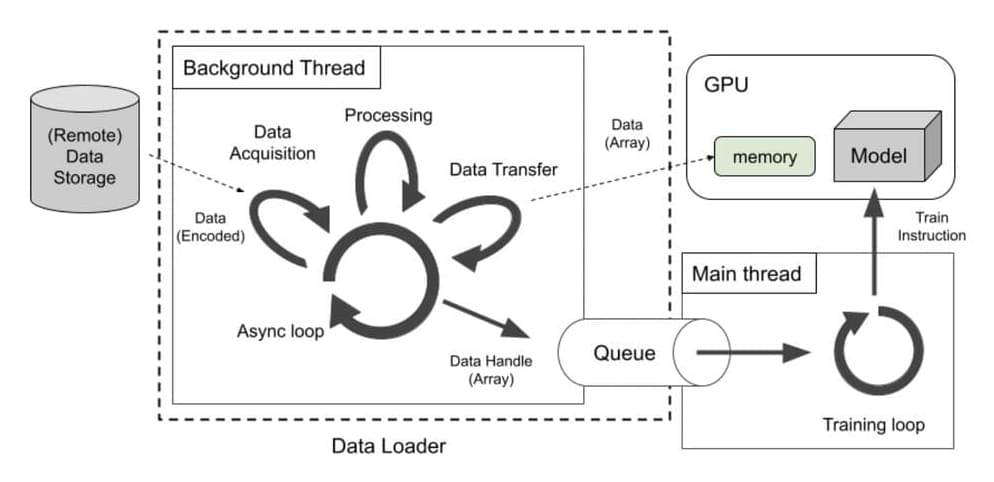
Training AI models today isn’t just about designing better architectures—it’s also about managing data efficiently. Modern models require vast datasets and need those datasets delivered quickly to GPUs and other accelerators. The problem? Traditional data loading systems often lag behind, slowing everything down. These older systems rely heavily on process-based methods that struggle to keep up with the demand, leading to GPU downtime, longer training sessions, and higher costs. This becomes even more frustrating when you’re trying to scale up or work with a mix of data types.
To tackle these issues, Meta AI has developed SPDL (Scalable and Performant Data Loading), a tool designed to improve how data is delivered during AI training. SPDL uses thread-based loading, which is a departure from the traditional process-based approach, to speed things up. It handles data from all sorts of sources—whether you’re pulling from the cloud or a local storage system—and integrates it seamlessly into your training workflow.
SPDL was built with scalability in mind. It works across distributed systems, so whether you’re training on a single GPU or a large cluster, SPDL has you covered. It’s also designed to work well with PyTorch, one of the most widely used AI frameworks, making it easier for teams to adopt. And since it’s open-source, anyone can take advantage of it or even contribute to its improvement.