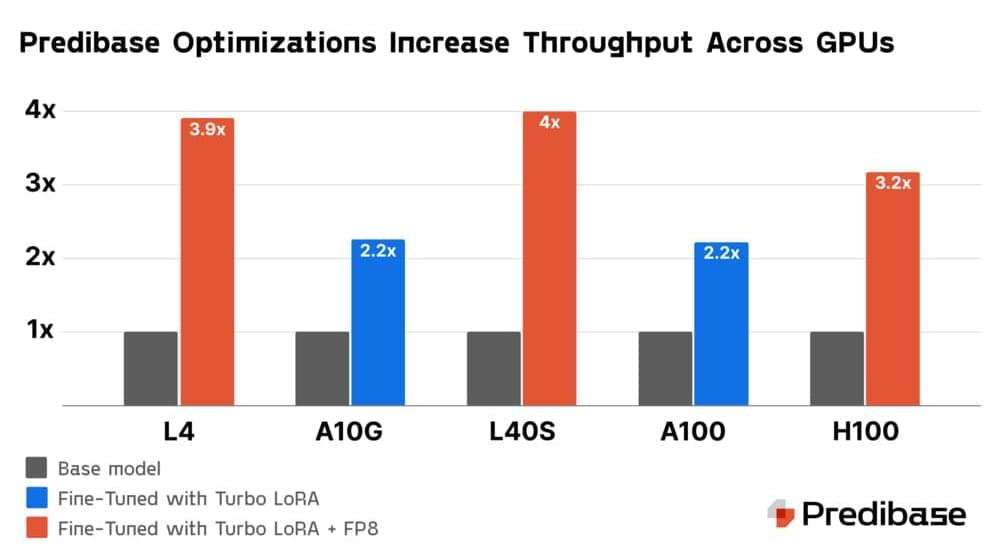
Predibase announces the Predibase Inference Engine, their new infrastructure offering designed to be the best platform for serving fine-tuned small language models (SLMs). The Predibase Inference Engine dramatically improves SLM deployments by making them faster, easily scalable, and more cost-effective for enterprises grappling with the complexities of productionizing AI. Built on Predibase’s innovations–Turbo LoRA and LoRA eXchange (LoRAX)–the Predibase Inference Engine is designed from the ground up to offer a best-in-class experience for serving fine-tuned SLMs.
The need for such an innovation is clear. As AI becomes more entrenched in the fabric of enterprise operations, the challenges associated with deploying and scaling SLMs have grown increasingly daunting. Homegrown infrastructure is often ill-equipped to handle the dynamic demands of high-volume AI workloads, leading to inflated costs, diminished performance, and operational bottlenecks. The Predibase Inference Engine addresses these challenges head-on, offering a tailor-made solution for enterprise AI deployments.
Join Predibase webinar on October 29th to learn more about the Predibase Inference Engine!