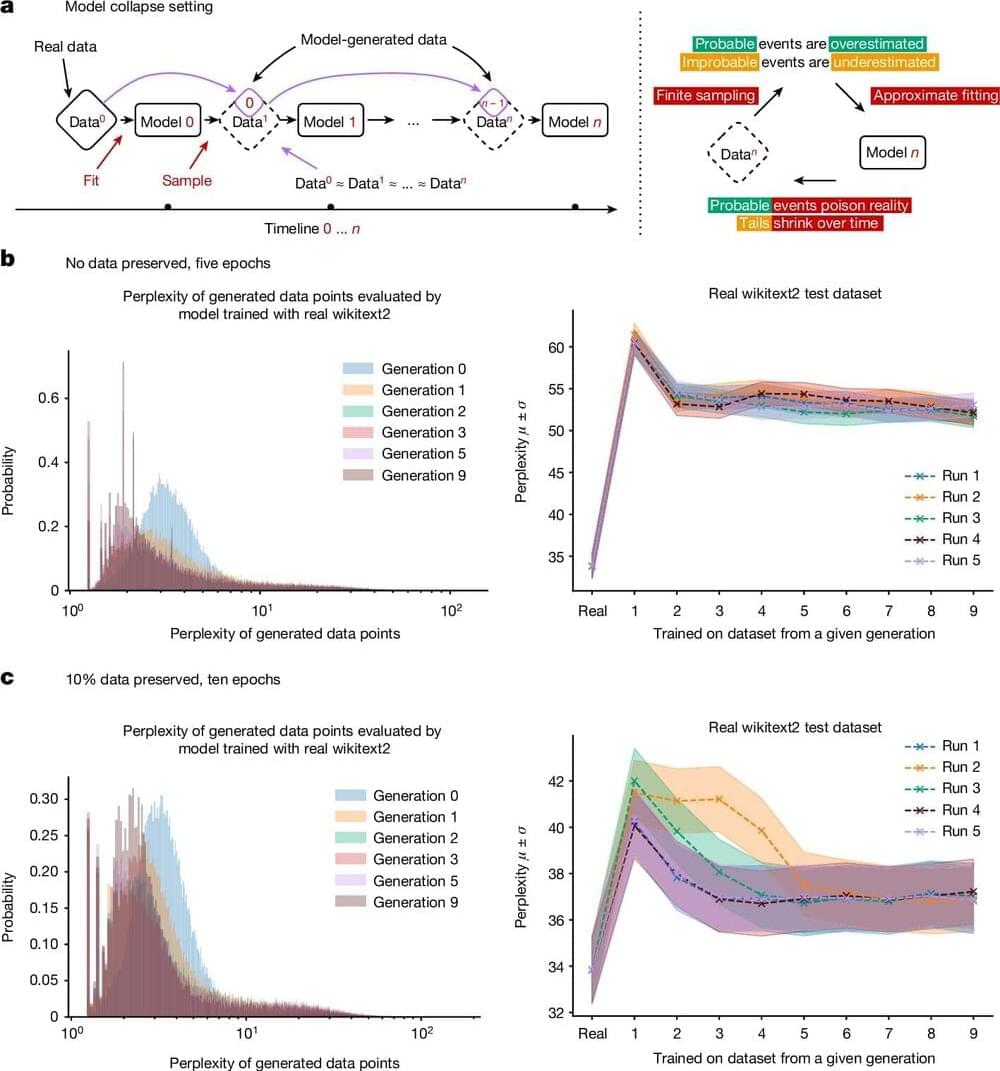
Using AI-generated datasets to train future generations of machine learning models may pollute their output, a concept known as model collapse, according to a new paper published in Nature. The research shows that within a few generations, original content is replaced by unrelated nonsense, demonstrating the importance of using reliable data to train AI models.
Generative AI tools such as large language models (LLMs) have grown in popularity and have been primarily trained using human-generated inputs. However, as these AI models continue to proliferate across the Internet, computer-generated content may be used to train other AI models—or themselves—in a recursive loop.
Ilia Shumailov and colleagues present mathematical models to illustrate how AI models may experience model collapse. The authors demonstrate that an AI may overlook certain outputs (for example, less common lines of text) in training data, causing it to train itself on only a portion of the dataset.