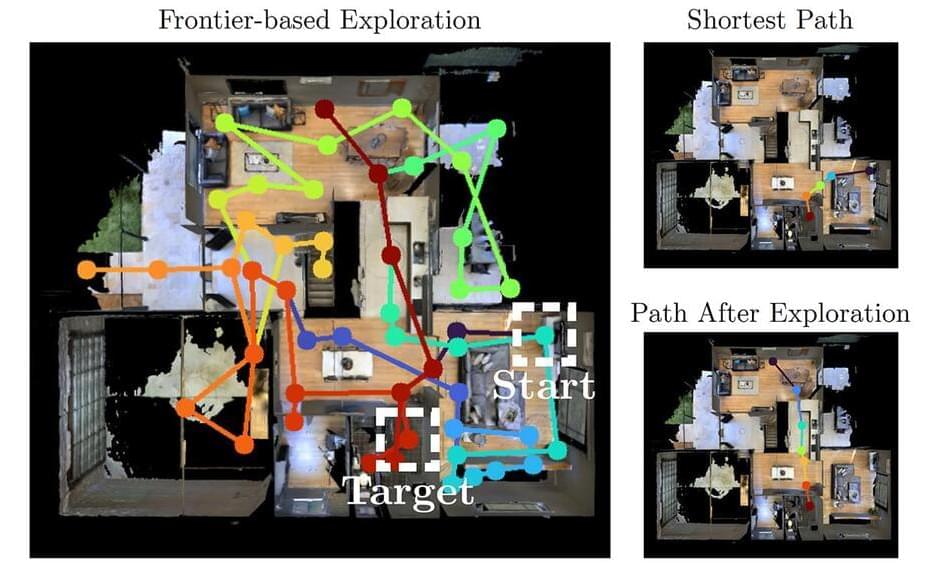
Oct 142023 Teaching household robots where to find requested objects Leveraging a large vision-language foundation model enables state-of-the-art performance in remote-object grounding.