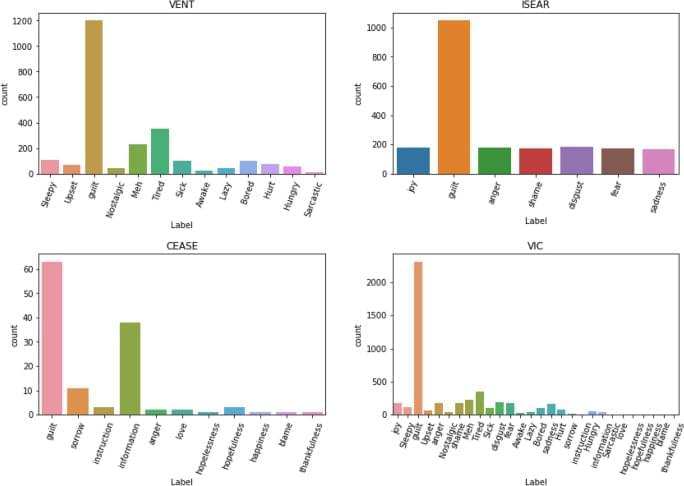
We introduce a novel Natural Language Processing (NLP) task called guilt detection, which focuses on detecting guilt in text. We identify guilt as a complex and vital emotion that has not been previously studied in NLP, and we aim to provide a more fine-grained analysis of it. To address the lack of publicly available corpora for guilt detection, we created VIC, a dataset containing 4,622 texts from three existing emotion detection datasets that we binarized into guilt and no-guilt classes. We experimented with traditional machine learning methods using bag-of-words and term frequency-inverse document frequency features, achieving a 72% f1 score with the highest-performing model. Our study provides a first step towards understanding guilt in text and opens the door for future research in this area.