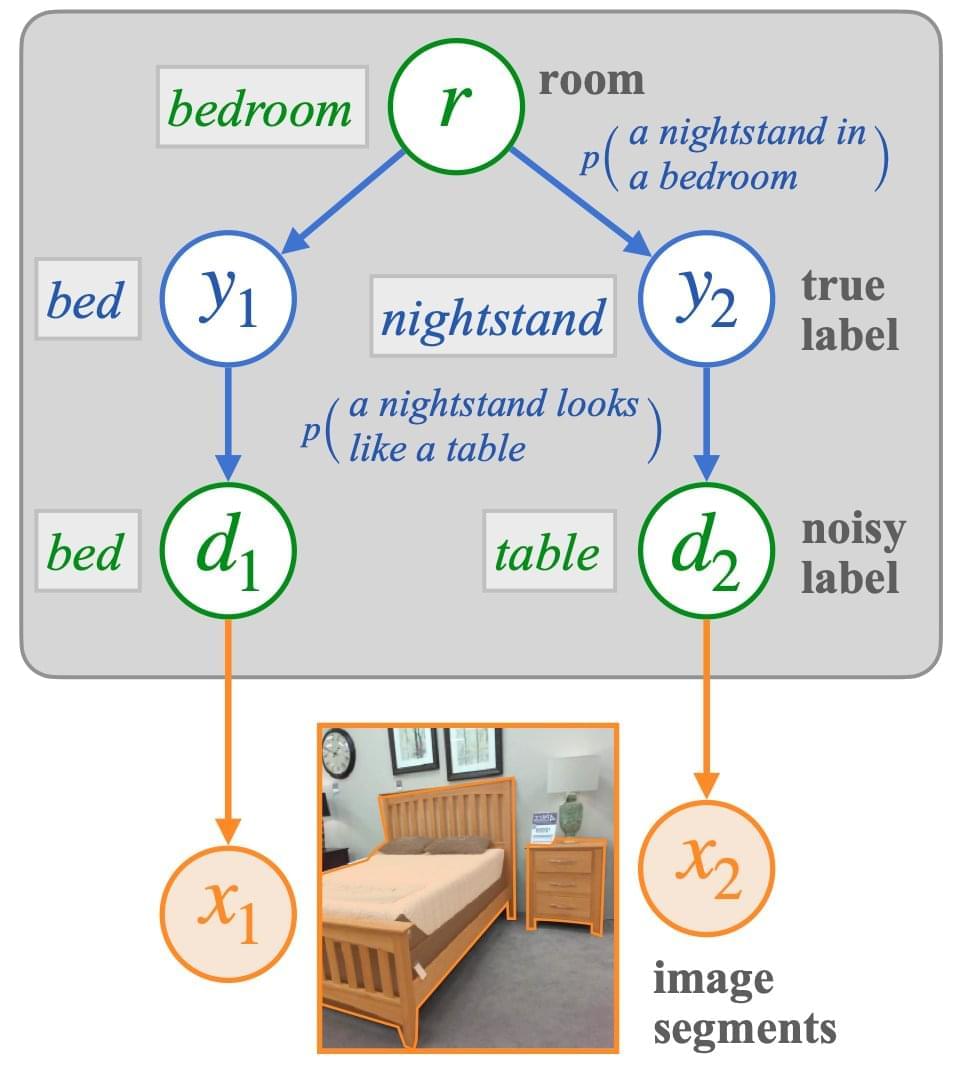
Common sense priors are essential to make decisions under uncertainty in real-world settings. Let’s say they want to give the scenario in Fig. 1 some labels. As a few key elements are recognized, it becomes evident that the image shows a restroom. This assists in resolving some of the labels for certain more difficult objects, such as the shower curtain in the scene rather than the window curtain and the mirror instead of the portrait on the wall. In addition to visual tasks, prior knowledge of expected item or event co-occurrences is crucial for navigating new environments and comprehending the actions of other agents. Moreover, such expectations are essential to object categorization and reading comprehension.
Unlike robot demos or segmented pictures, vast text corpora are easily accessible and include practically all aspects of the human experience. Current machine learning models use task-specific datasets to learn about the previous distribution of labels and judgments for the majority of problem domains. When training data is skewed or sparse, this can lead to systematic mistakes, particularly on uncommon or out-of-distribution inputs. How might they provide models with broader, more adaptable past knowledge? They suggest using learned distributions over natural language strings known as language models as task-general probabilistic priors.
LMs have been employed as sources of prior knowledge for tasks ranging from common-sense question answering to modeling scripts and tales to synthesizing probabilistic algorithms in language processing and other text production activities. They frequently give higher diversity and fidelity than small, task-specific datasets for encoding much of this information, such as the fact that plates are found in kitchens and dining rooms and that breaking eggs comes before whisking them. It has also been proposed that such language monitoring contributes to common-sense human knowledge in areas that are challenging to learn from first-hand experience.