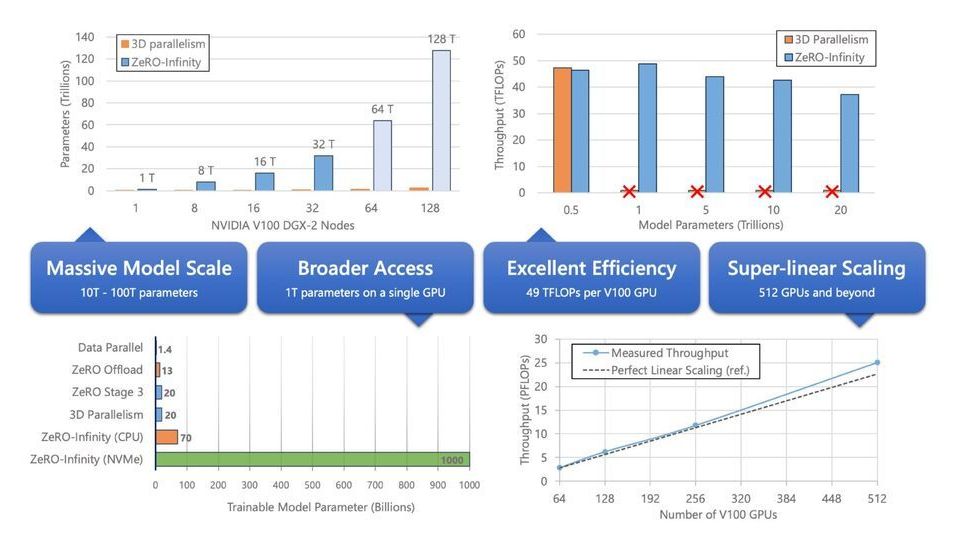
Since the DeepSpeed optimization library was introduced last year, it has rolled out numerous novel optimizations for training large AI models—improving scale, speed, cost, and usability. As large models have quickly evolved over the last year, so too has DeepSpeed. Whether enabling researchers to create the 17-billion-parameter Microsoft Turing Natural Language Generation (Turing-NLG) with state-of-the-art accuracy, achieving the fastest BERT training record, or supporting 10x larger model training using a single GPU, DeepSpeed continues to tackle challenges in AI at Scale with the latest advancements for large-scale model training. Now, the novel memory optimization technology ZeRO (Zero Redundancy Optimizer), included in DeepSpeed, is undergoing a further transformation of its own. The improved ZeRO-Infinity offers the system capability to go beyond the GPU memory wall and train models with tens of trillions of parameters, an order of magnitude bigger than state-of-the-art systems can support. It also offers a promising path toward training 100-trillion-parameter models.
ZeRO-Infinity at a glance: ZeRO-Infinity is a novel deep learning (DL) training technology for scaling model training, from a single GPU to massive supercomputers with thousands of GPUs. It powers unprecedented model sizes by leveraging the full memory capacity of a system, concurrently exploiting all heterogeneous memory (GPU, CPU, and Non-Volatile Memory express or NVMe for short). Learn more in our paper, “ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning.” The highlights of ZeRO-Infinity include: