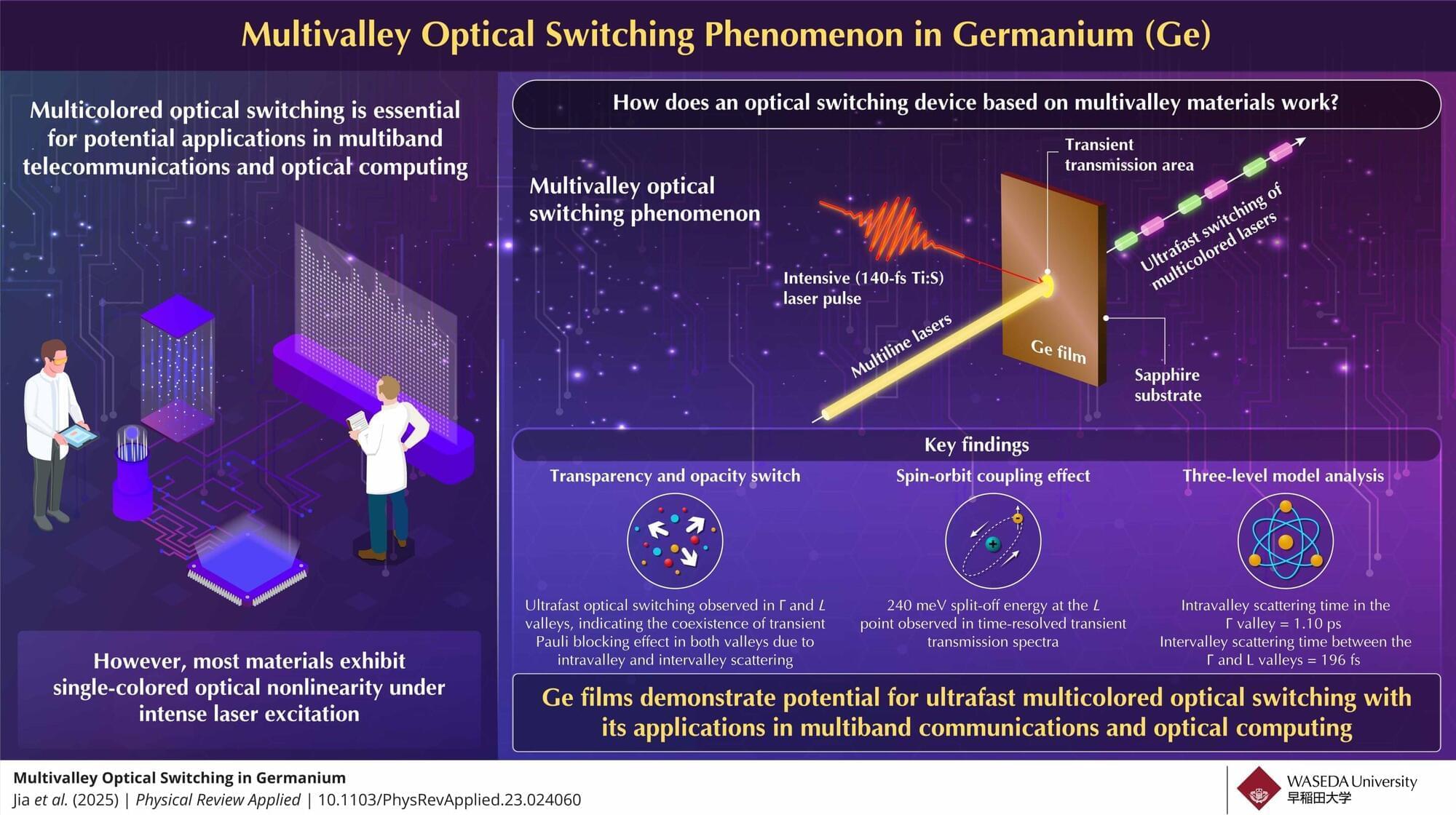
Opaque materials can transmit light when excited by a high-intensity laser beam. This process, known as optical bleaching, induces a nonlinear effect that temporarily alters the properties of a material. Remarkably, when the laser is switched on and off at ultrahigh speeds, the effect can be dynamically controlled, opening new possibilities for advanced optical technologies.
Multicolored optical switching is an important phenomenon with potential applications in fields such as telecommunications and optical computing. However, most materials typically exhibit single-color optical nonlinearity under intense laser illumination, limiting their use in systems requiring multicolor or multiband switching capabilities. Currently, most optical switches are based on microelectromechanical systems, which require an electric voltage or current to operate, resulting in slow response times.
To address this gap, a group of researchers, led by Professor Junjun Jia from the Faculty of Science and Engineering at Waseda University, Japan, in collaboration with Professor Hui Ye and Dr. Hossam A. Almossalami from the College of Optical Science and Engineering at Zhejiang University, China, Professor Naoomi Yamada from the Department of Applied Chemistry at Chubu University, Japan, and Dr. Takashi Yagi from the National Institute of Advanced Industrial Science and Technology, Japan, investigated the multivalley optical switching phenomenon in germanium (Ge) films.