Two cannabis-derived compounds have shown remarkable effectiveness against fungal pathogens in laboratory tests, according to new Macquarie University research.
Promise: Dr Hue Dinh, pictured, and colleagues at the Macquarie University Galleria laboratory are hopeful their discovery will lead to new treatments for common skin infections.
In a study published in The Journal of Neglected Tropical Diseases (PLOS NTDs), researchers discovered that bioactives Cannabidiol (CBD) and Cannabidivarin (CBDV) killed harmful Cryptococcus neoformans - a WHO-listed priority fungal pathogen. The compounds also killed dermatophytes that cause common skin infections, and much faster than existing treatments.
The chemical reaction to produce hydrogen from water is several times more effective when using a combination of new materials in three layers, according to researchers at Linköping University in Sweden. Hydrogen produced from water is a promising renewable energy source—especially if the hydrogen is produced using sunlight.
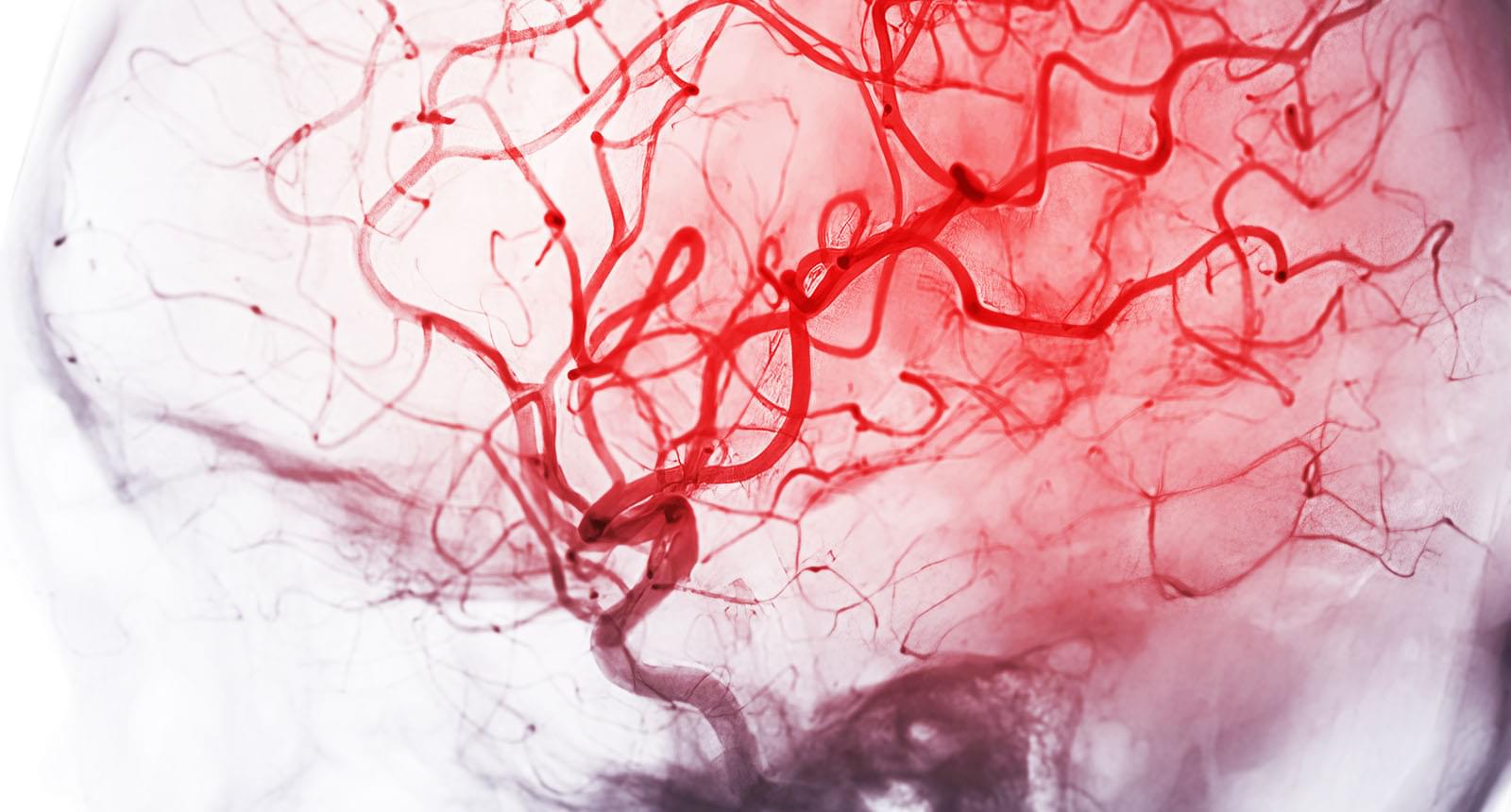
All day long, our brains carry out complicated and energy-intensive tasks such as remembering, solving problems, and making decisions.
To supply the energy these tasks require while conserving this precious fuel, the brain has evolved a system that allows it to quickly and efficiently send blood only to the areas that need it most in any given moment. This system is essential to brain function and overall health, yet how it works has remained somewhat of a mystery.
Now, a team led by researchers at Harvard Medical School has uncovered new details of how the brain moves blood to active areas in real time. Their findings are published July 16 in Cell.
In experiments in mice, the team discovered that the brain uses specialized channels in the lining of its blood vessels to communicate where blood is needed.
“This work helps us understand how you can get that super-important blood supply to the correct areas of the brain on a time scale that is useful,” said co-lead author Luke Kaplan, a research fellow in neurobiology in the Blavatnik Institute at HMS.
If confirmed in additional studies in animals and humans, the findings could be used to better understand findings on brain imaging tests such as functional MRI (fMRI). The insights may also advance understanding of neurodegenerative diseases, in which this communication system often breaks down, leading to cognitive problems.
Physicist and fusion researcher Eric Lerner presents a sweeping critique of the Big Bang theory and the standard model of cosmology at Demysticon 25. He builds on the foundations of plasma physics and the work of Nobel laureate Hannes Alfvén to outline an alternative cosmological framework rooted in known physical laws—gravity, nuclear fusion, and electromagnetic plasma behavior—rather than hypothetical concepts like dark matter, dark energy, or cosmic inflation. He explores how filamentary plasma structures may account for galaxy formation, how fusion research using dense plasma focus devices parallels cosmic processes, and how the cosmic microwave background may not be relic radiation from a singular origin. Merging astrophysics, plasma cosmology, and energy research, this talk reframes the origin and structure of the universe—and calls into question the prevailing narratives at the heart of modern theoretical physics.
PATREON / demystifysci.
PARADIGM DRIFT https://demystifysci.com/paradigm-dri… Go! Introduction the Big Bang Debate 00:03:57 Eric Lerner’s Perspective on Cosmic Evolution 00:04:21 The Pinch Effect and Electrical Currents in Plasmas 00:10:27 Evolutionary Hierarchies and Cosmic Filaments 00:14:50 Interplay of Forces in Structure Formation 00:18:14 Evidence of Filaments Across Scales 00:25:04 Dynamics of Galaxy Formation and Star Development 00:29:08 Cosmic Microwave Background and Element Formation 00:30:29 The Formation and Properties of Early Galaxies 00:35:22 Energy Flows and the Cosmic Evolution Crisis 00:39:58 Plasma Focus Devices and Fusion Energy Research 00:41:16 Q&A Understanding Galaxy Components and Rotation 00:51:33 Q&A The Implications of Missing Gravity and Galaxy Dynamics 00:58:07 Q&A Gravitational Lensing and Mass Distribution 01:00:32 Q&A Lensing and Galactic Observations 01:02:04 Q&A Fractal Patterns in Cosmology #cosmology, #space, #galaxyformation, #gravitationalwaves, #cosmicstructures, #astrophysics, #fusionenergy, #magneticfields, #spacephysics, #electricuniverse, #criticalthinking #philosophypodcast, #sciencepodcast, #longformpodcast ABOUS US: Anastasia completed her PhD studying bioelectricity at Columbia University. When not talking to brilliant people or making movies, she spends her time painting, reading, and guiding backcountry excursions. Shilo also did his PhD at Columbia studying the elastic properties of molecular water. When he’s not in the film studio, he’s exploring sound in music. They are both freelance professors at various universities. PATREON: get episodes early + join our weekly Patron Chat https://bit.ly/3lcAasB MERCH: Rock some DemystifySci gear : https://demystifysci.myspreadshop.com… AMAZON: Do your shopping through this link: https://amzn.to/3YyoT98 DONATE: https://bit.ly/3wkPqaD SUBSTACK: https://substack.com/@UCqV4_7i9h1_V7h… BLOG: http://DemystifySci.com/blog RSS: https://anchor.fm/s/2be66934/podcast/rss MAILING LIST: https://bit.ly/3v3kz2S SOCIAL:
00:00 Go! Introduction the Big Bang Debate. 00:03:57 Eric Lerner’s Perspective on Cosmic Evolution. 00:04:21 The Pinch Effect and Electrical Currents in Plasmas. 00:10:27 Evolutionary Hierarchies and Cosmic Filaments. 00:14:50 Interplay of Forces in Structure Formation. 00:18:14 Evidence of Filaments Across Scales. 00:25:04 Dynamics of Galaxy Formation and Star Development. 00:29:08 Cosmic Microwave Background and Element Formation. 00:30:29 The Formation and Properties of Early Galaxies. 00:35:22 Energy Flows and the Cosmic Evolution Crisis. 00:39:58 Plasma Focus Devices and Fusion Energy Research. 00:41:16 Q&A Understanding Galaxy Components and Rotation. 00:51:33 Q&A The Implications of Missing Gravity and Galaxy Dynamics. 00:58:07 Q&A Gravitational Lensing and Mass Distribution. 01:00:32 Q&A Lensing and Galactic Observations. 01:02:04 Q&A Fractal Patterns in Cosmology.
ABOUS US: Anastasia completed her PhD studying bioelectricity at Columbia University. When not talking to brilliant people or making movies, she spends her time painting, reading, and guiding backcountry excursions. Shilo also did his PhD at Columbia studying the elastic properties of molecular water. When he’s not in the film studio, he’s exploring sound in music. They are both freelance professors at various universities.
In this video we look at the thought of French Paleontologist, Cosmologist, WWI veteran and Jesuit Priest, Teilhard De Chardin, and his conceptions of the Omega Point and the Noosphere as articulated in his most significant work, The Phenomenon of Man.
By heating and cooling a quantum material called 1T-TaS₂, researchers were able to control its conductive properties, showing that this type of material could speed up electronic processing one thousand fold.