Researchers have measured the brain’s faint glow for the first time, hinting at a potential role of “biophotons” in cognition
The brain is constantly mapping the external world like a GPS, even when we don’t know about it. This activity comes in the form of tiny electrical signals sent between neurons—specialized cells that communicate with one another to help us think, move, remember and feel. These signals often follow rhythmic patterns known as brain waves, such as slower theta waves and faster gamma waves, which help organize how the brain processes information.
Understanding how individual neurons respond to these rhythms is key to unlocking how the brain functions related to navigation in real time—and how it may be affected in disease.
A new study by Florida Atlantic University and collaborators from Erasmus Medical Center, Rotterdam, Netherlands, and the University of Amsterdam, Netherlands, has uncovered a surprising ability of brain cells in the hippocampus to process and encode and respond to information from multiple brain rhythms at once.

Earthworms often form a cluster, from which they can barely free themselves. A similarly active, writhing structure forms when the tentacles of lion’s mane jellyfish become entangled. Robotic grippers utilize this principle by using multiple synthetic flexible arms to grip and move objects. And such interlinked self-propelled filaments can also be found at the smaller micrometer scale, for example in a biological cell.
Late last week, Israel targeted three of Iran’s key nuclear facilities—Natanz, Isfahan and Fordow, killing several Iranian nuclear scientists. The facilities are heavily fortified and largely underground, and there are conflicting reports of how much damage has been done.
Natanz and Fordow are Iran’s uranium enrichment sites, and Isfahan provides the raw materials, so any damage to these sites would limit Iran’s ability to produce nuclear weapons.
But what exactly is uranium enrichment and why does it raise concerns?

A new filter for infrared light could see scanning and screening technology tumble in price and size. Built on nanotechnology, the new heat-tunable filter promises hand-held, robust technology to replace current desktop infrared spectroscopy setups that are bulky, heavy and cost from $10,000 up to more than $100,000.
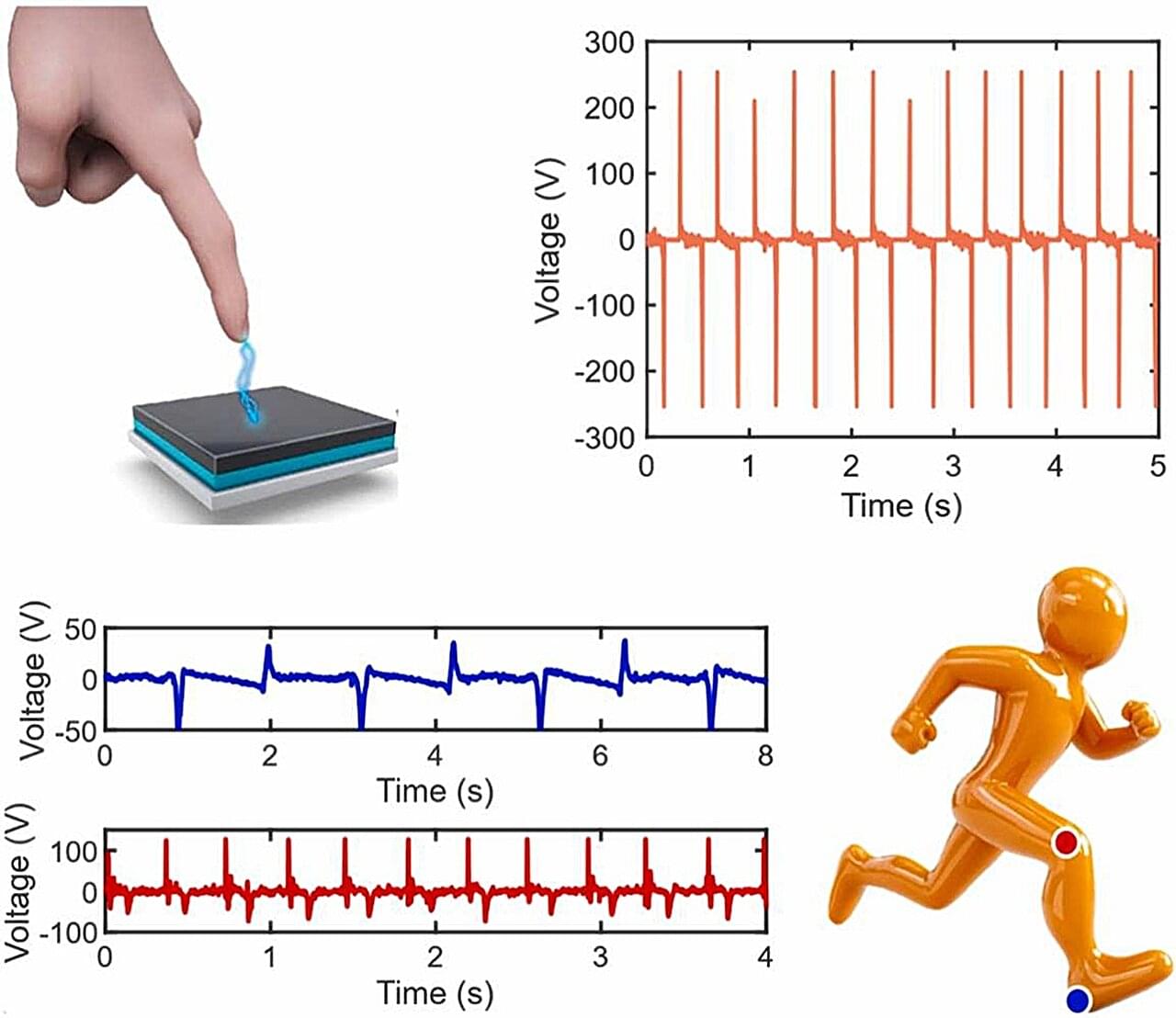
Researchers at Boise State University have developed a novel, environmentally friendly triboelectric nanogenerator (TENG) that is fully printed and capable of harvesting biomechanical and environmental energy while also functioning as a real-time motion sensor. The innovation leverages a composite of Poly (vinyl butyral-co-vinyl alcohol-co-vinyl acetate) (PVBVA) and MXene (Ti3C2Tx) nanosheets, offering a sustainable alternative to conventional TENGs that often rely on fluorinated polymers and complex fabrication.
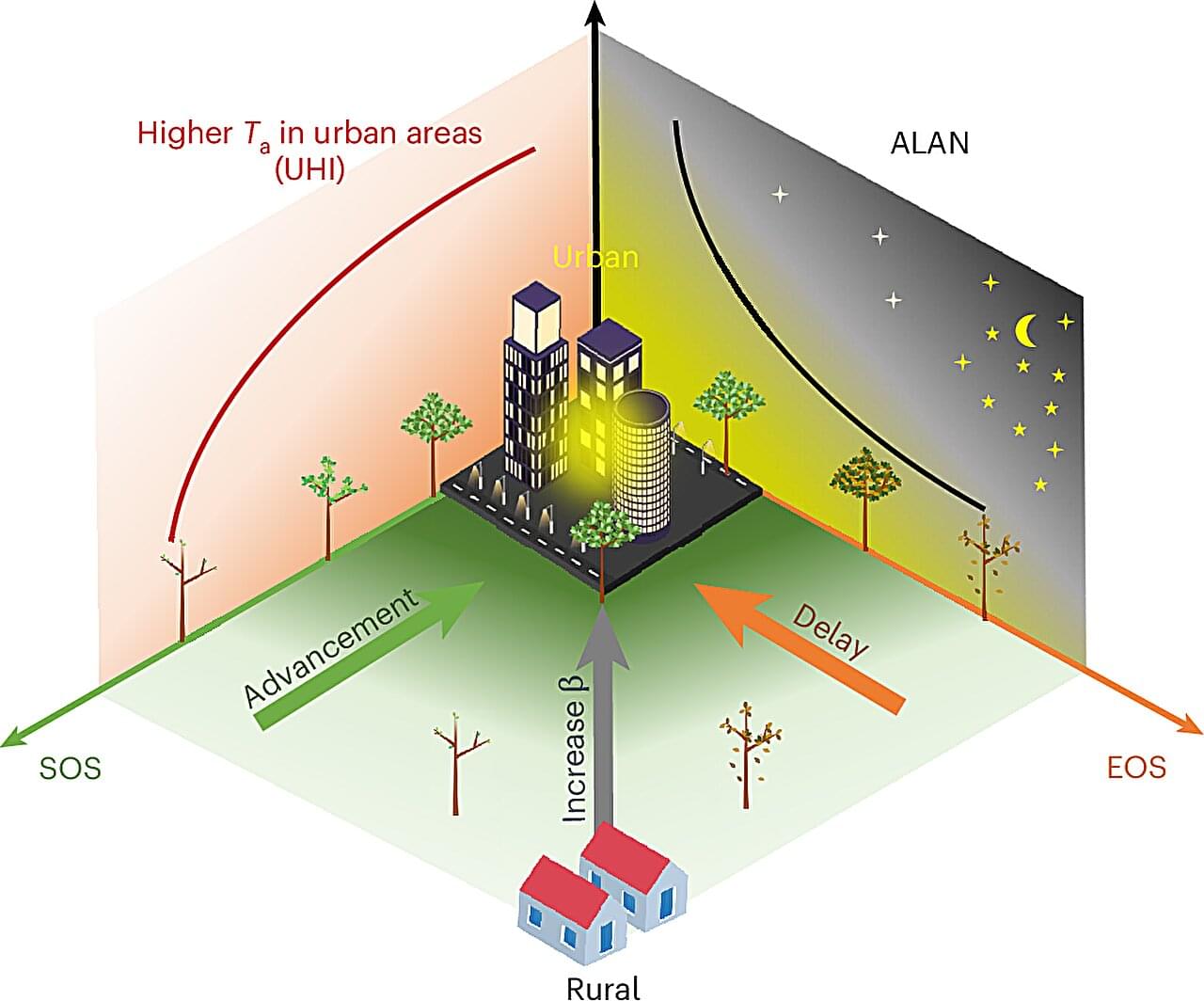
Artificial light may be lengthening the growing season in urban environments by as much as 3 weeks compared to rural areas, according to an analysis of satellite data from 428 urban centers in the Northern Hemisphere over 7 years, published in Nature Cities.
Rapid urbanization is leading to hotter and brighter cities. More specifically, buildings and concrete absorb and radiate heat, causing urban heat islands, in which urban areas have higher atmospheric temperatures throughout the day and night compared to their surroundings. Likewise, the amount of artificial light at night has increased by 10% in cities within the past decade.
Light and temperature also largely regulate plant growing seasons. For example, increased lighting and temperature cause trees in cities to bud and flower earlier in the spring and change color later in the autumn than trees in rural surroundings. However, research has not thoroughly studied the magnitude of their individual or combined impacts.

{kind=link}