The startup tested its technology on primates for several years.


Supersonic airplanes are old news. But supersonic airplanes that can fly nine times the speed of sound? That’s something else.
Texas-based company Venus Aerospace is designing a passenger plane called Stargazer that’s capable of flying at Mach 9, or approximately 6,900 miles per hour — which means you’d be able to fly from New York to Sydney in less than 90 minutes. By comparison, the Concorde, which was the only supersonic passenger plane ever to fly commercially, flew at about Mach 2, or more than 1,500 miles per hour.


Electron, Rocket Lab’s small satellite launch vehicle, launched twice, just ~2 weeks apart from the companies Launch Complex 1 in Mahia, New Zealand to deliver the 4 CubeSat constellation to orbit.
Payload deployment confirmed! Congratulations to the launch team on our 37th Electron launch, and to our mission partners at @NASA @NASA_LSP @NASAAmes: the TROPICS constellation is officially on orbit! pic.twitter.com/xAy7ltg7m1
The two missions, dubbed ‘Rocket Like a Hurricane’ and ‘Coming to a Storm Near You,’ contain two 11.8-lb (5.34 kg) CubeSats each delivered to a 30-degree orbital inclination in order for the constellation to monitor tropical systems forming in the Atlantic and Pacific Ocean and will be capable of performing scans about once every hour.

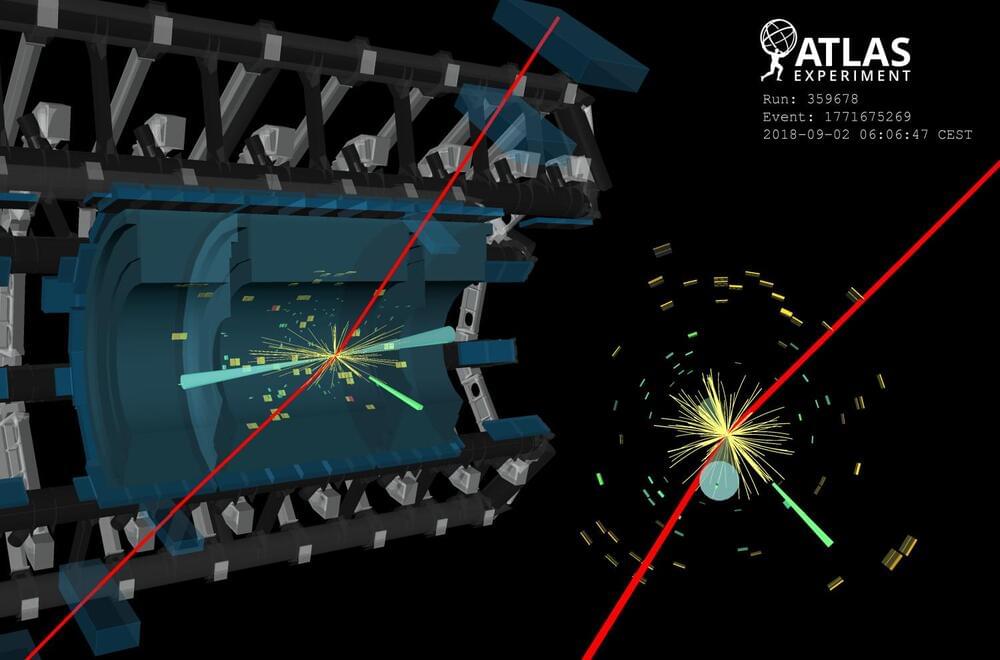
The discovery of the Higgs boson in 2012 marked a significant milestone in particle physics. Since then, researchers at the ATLAS and CMS Collaborations have been diligently investigating its properties and probing for rare production and decay channels. Among the rare decays, the process where the Higgs boson decays into a Z boson and a photon (H → Zγ) has raised considerable attention, especially given the significant dataset collected during Run 2 of the Large Hadron Collider. Figure 1: The Zγ invariant mass distribution of events from all ATLAS and CMS analysis categories. The data (circles with error bars) in each category are weighted by ln(1 + S/B) and summed, where S and B are the observed signal and background yields in that category and in the 120–130 GeV interval, derived from the fit to data. The fitted signal-plus-background (background) terms are represented by a red solid (blue dashed) line. In the lower panel, the data and the two models are compared after subtraction of the estimated background. (Image: CERN) This is a special kind of decay – the Higgs boson does not couple directly to the Zγ pair; instead, the decay proceeds via an intermediate ‘loop’ of virtual particles. Thus, in the Standard Model, the decay probability (or branching fraction) for H → Zγ is predicted to be small – around 1.5 ×10–3, for a Higgs boson mass near 125 GeV. Theories that go beyond the Standard Model predict this branching fraction to deviate, as new particles interacting with the Higgs boson may also contribute to this loop. Exploring these variations provides valuable insights into both physics beyond the Standard Model and the nature of the Higgs boson. The ATLAS and CMS Collaborations have independently conducted extensive searches for the H → Zγ process. Both searches employ similar strategies, reconstructing the Z boson through its decays into pairs of electrons or muons. Signal events are identified as a narrow peak in the Zγ invariant mass distribution. To enhance the sensitivity, researchers exploited the most frequent Higgs-boson production modes and categorised events based on the characteristics of these production processes. They also used advanced machine-learning techniques, such as boosted decision trees, to distinguish between signal and background events. The ATLAS and CMS Collaborations have joined forces to report first evidence of the H → Zγ decay, with a significance of 3.4 standard deviations. Figure 2: Negative log-likelihood scan of the signal strength μ from the analysis of ATLAS data (blue line), CMS data (red line), and the combined result (black line). (Image: CERN) Recognising the importance of this decay channel, the ATLAS and CMS Collaborations joined forces to maximise the statistical power and sensitivity of their analyses. By combining the data sets collected by both experiments during Run 2 of the LHC (2015−2018), researchers have significantly increased the statistical precision and expanded the reach of their search. This collaborative effort allowed for a more precise and robust measurement. Figure 1 displays the observed distribution of the mass of the Zγ system in the combined data sample. Figure 2 presents the negative log-likelihood scan to identify the most likely signal strength that best describes the observed data. The signal strength (μ) is defined as the ratio of the Higgs-boson production cross-section times the H → Zγ decay branching fraction to its Standard-Model prediction. This analysis reveals evidence for the H → Zγ decay, with a significance of 3.4 standard deviations. This means that the probability that this signal is actually caused by a statistical fluctuation is smaller than 0.04%. The measured branching fraction for H → Zγ is 3.4 ± 1.1 ×10–3 and the observed signal yield is measured to be 2.2 ± 0.7 times the Standard-Model prediction. This means that the decay is seen a little more than twice as often as would be expected by the Standard Model. Although the uncertainty on the present measurement is still quite large, these findings open the door to valuable insights into the behaviour and properties of the Higgs boson. Looking ahead, by the end of LHC Run 3 the collected data is expected to triple the size of the dataset analysed here. This will allow ATLAS and CMS researchers to study this rare decay channel in even more detail, and to use this channel to probe for new physics beyond the Standard Model. About the event display: Event display of a candidate H→ Zγ event with the Z boson decaying μ+μ-. The transverse momenta of the two muon candidates, shown in red. The photon candidate is reconstructed as an unconverted photon with a transverse momentum of 32.5 GeV. Two jets are represented by light blue cones. The green boxes correspond to energy deposits in cells of the electromagnetic calorimeter, while yellow boxes correspond to energy deposits in cells of the hadronic calorimeter. Learn more Evidence for the Higgs boson decay to a Z boson and a photon at the LHC (ATLAS-CONF-2023–025) LHCP 2023 presentation by Toyoko Orimoto: Higgs boson rare production and decay at ATLAS and CMS LHCP 2023 presentation by Chiara Arcangeletti: Measurement of Higgs boson production and properties LHC experiments see first evidence for rare Higgs boson decay into two different bosons, CMS briefing, May 2023 ATLAS Collaboration: A search for the Zγ decay mode of the Higgs boson in pp collisions at 13 TeV with the ATLAS detector (Phys. Lett. B 809 (2020) 135,754, arXiv: 2005.05382, see figures) CMS Collaboration: Search for Higgs boson decays to a Z boson and a photon in proton–proton collisions at 13 TeV (Accepted for publication in J. High Energy Phys, arXiv: 2204.12945, see figures) ATLAS searches for rare Higgs boson decays into a photon and a Z boson, ATLAS Physics Briefing, April 2020 A possible new decay mode of the Higgs boson, CMS briefing, April 2022 Summary of new ATLAS results from LHCP 2023, ATLAS News, May 2023.
A recent study published in the journal Scientific Reports assessed the associations between the change in total cholesterol (TC) levels after type 2 diabetes (T2D) diagnosis (relative to pre-diagnosis levels) and the risk of cardiovascular disease (CVD).
CVD is the global leading cause of mortality. T2D is a gateway disease to CVD. A study revealed higher coronary heart disease (CHD) and stroke risks in diabetes patients than in non-diabetic individuals. The global prevalence of T2D is expected to exceed 10% by 2030. Therefore, preventing CVD in people with diabetes could be of public health significance.
Hypercholesterolemia is a significant risk factor for CVD, and its adverse effects on CVD could be more evident in individuals with metabolic conditions, e.g., T2D. Diabetes patients may be more susceptible to hypercholesterolemia’s negative impact on CVD risk. Nonetheless, T2D diagnosis often results in positive lifestyle changes helping reduce hypercholesterolemia or CVD risk.

Finding the best quantum computing stocks to buy is critical because this is clearly the next big industry.
Quantum computers promise to bring the power of quantum mechanics to bear in solving our most vexing problems. They may be capable of processing more data, faster, than any classical computer.
If all that happens, then quantum computing stocks may bring generational wealth to their investors.
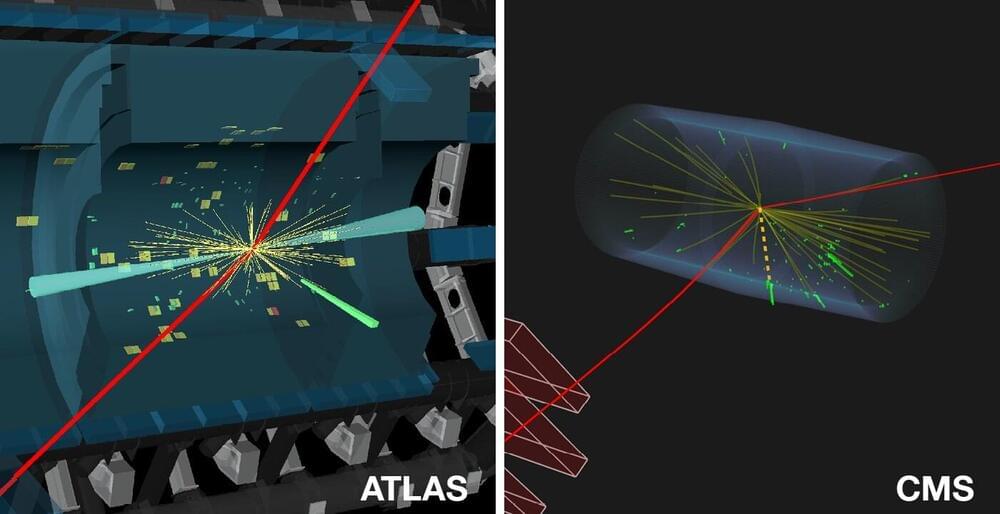
The discovery of the Higgs boson at CERN’s Large Hadron Collider (LHC) in 2012 marked a significant milestone in particle physics. Since then, the ATLAS and CMS collaborations have been diligently investigating the properties of this unique particle and searching to establish the different ways in which it is produced and decays into other particles.
At the Large Hadron Collider Physics (LHCP) conference this week, ATLAS and CMS report how they teamed up to find the first evidence of the rare process in which the Higgs boson decays into a Z boson, the electrically neutral carrier of the weak force, and a photon, the carrier of the electromagnetic force. This Higgs boson decay could provide indirect evidence of the existence of particles beyond those predicted by the Standard Model of particle physics.
The decay of the Higgs boson into a Z boson and a photon is similar to that of a decay into two photons. In these processes, the Higgs boson does not decay directly into these pairs of particles. Instead, the decays proceed via an intermediate “loop” of “virtual” particles that pop in and out of existence and cannot be directly detected. These virtual particles could include new, as yet undiscovered particles that interact with the Higgs boson.

ChatGPT has been a topic of great discussion in academia, particularly about how to prevent its unauthorized use in classes. However, students can benefit from understanding how to use generative artificial intelligence (AI) as a tool to save time and improve performance on writing assignments.
Craig Hurwitz, an Executive in Residence in the Pratt School of Engineering, asked the graduate students in his “Emerging Trends in Financial Technology (Fintech)” course to generate a first draft of an essay with ChatGPT’s help. His working assumption was that when students enter the workforce they will have access to, and the ability to use, generative AI for productivity purposes. He wanted to experiment with ChatGPT in his course to give students a first-hand look at how to use generative AI.
For the assignment, the class was instructed to read a case study and each student chose a Fintech approach to help solve a particular challenge mentioned in the case. Their written assignment was a 750-word Executive Summary convincing the instructor (playing the role of Venture Capitalist) why he should consider meeting to discuss a potential investment.