Wait… how is that possible?
Get the latest international news and world events from around the world.


Scientists develop fermionic quantum processor
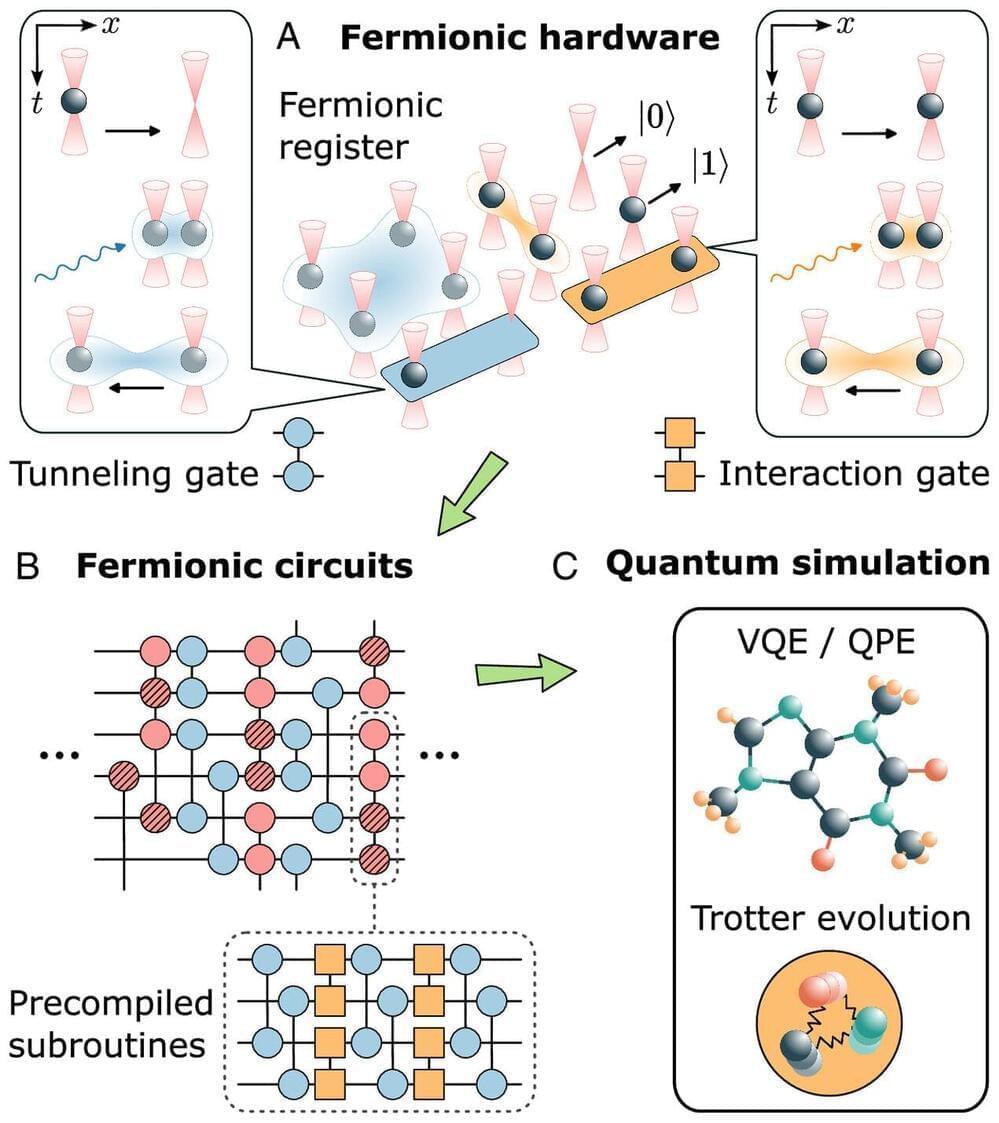
Researchers from Austria and the U.S. have designed a new type of quantum computer that uses fermionic atoms to simulate complex physical systems. The processor uses programmable neutral atom arrays and is capable of simulating fermionic models in a hardware-efficient manner using fermionic gates.
The team led by Peter Zoller demonstrated how the new quantum processor can efficiently simulate fermionic models from quantum chemistry and particle physics. The paper is published in the journal Proceedings of the National Academy of Sciences.
Fermionic atoms are atoms that obey the Pauli exclusion principle, which means that no two of them can occupy the same quantum state simultaneously. This makes them ideal for simulating systems where fermionic statistics play a crucial role, such as molecules, superconductors and quark-gluon plasmas.


Researchers Manipulating Time Cause First-Ever Successful Photon Collisions
Researchers have successfully forced electromagnetic (EM) waves that usually pass right through each other to collide head-on by manipulating time, made possible with the unique properties of metamaterials.
Inspired by the concept of using macro-scale waves like tsunamis or earthquakes to cancel each other out, the manipulation of time interfaces to cause these photons to collide instead of pass through each other could open up a wide range of engineering applications, including advances in telecommunications, optical computing, and even energy harvesting.
Is Using One Wave to Cancel Another Wave Possible?


Black Hole May Have Formed by Direct Collapse
Astronomers may have spotted a supermassive black hole in the early universe that formed when a gargantuan gas cloud imploded.
The black hole’s host galaxy, UHZ1, was spotted in James Webb Space Telescope (JWST) observations of galaxies in the early universe. These distant galaxies’ light has been bent and magnified by the intervening galaxy cluster Abell 2,744, bringing them into view.
Ákos Bogdán (Center for Astrophysics, Harvard & Smithsonian) and others used the Chandra X-ray Observatory to take a second look at 11 of the lensed galaxies. Based on which wavelengths the galaxies are detectable at, each of the 11 appeared to lie at a redshift greater than 9, which means they’re shining at us from the universe’s first 500 million years. The team picked up X-rays from just one galaxy, the most magnified of the bunch.
Joscha Bach, Yulia Sandamirskaya: “The Third Age of AI: Understanding Machines that Understand”
Discussion with Joscha Bach and Yulia Sandamirskaya, both Intel, at the Festival of the Future 2022 by 1E9 and Deutsches Museum.
When cognitive computing meets neuromorphic computing: In their indepth dialogue at the Festival of the Future Joscha Bach, Principal AI Engineer at Intel, and his colleague Yulia Sandamirskaya, who works as a Research Scientist at Intel in Munich approach the new era of AI from two fascinatingly different angles.
Joscha Bach / Principal AI Engineer, Cognitive Computing, Intel Labs.
Joscha Bach, PhD, is a cognitive scientist and AI researcher with a focus on computational models of cognition. He has taught and worked in AI research at Humboldt University of Berlin, the Institute for Cognitive Science in Osnabrück, the MIT media lab, the Harvard Program for Evolutionary Dynamics and is currently a principal AI researcher at Intel Labs, California.
Yulia Sandamirskaya /Research Scientist, Intel.
Yulia Sandamirskaya leads the Applications research team of the Neuromorphic Computing Lab at Intel in Munich, Germany. Before joining Intel she was a group leader at the Institute of Neuroinformatics at the University of Zurich and ETH Zurich, Switzerland and the Institute for Neural Computation at the Ruhr-University Bochum, Germany. Her research targets neural-dynamic architectures for embodied cognition, demonstrated using neuromorphic computing hardware and robotic systems.
If you like this content, check out the digital platform of 1E9:
https://1e9.community/
How the Brain Makes You: Collective Intelligence and Computation by Neural Circuits
Vijay Balasubramanian University of Pennsylvania, SFI The human brain consists of a 100 billion neurons connected by a 100 trillion synapses. In its computa…