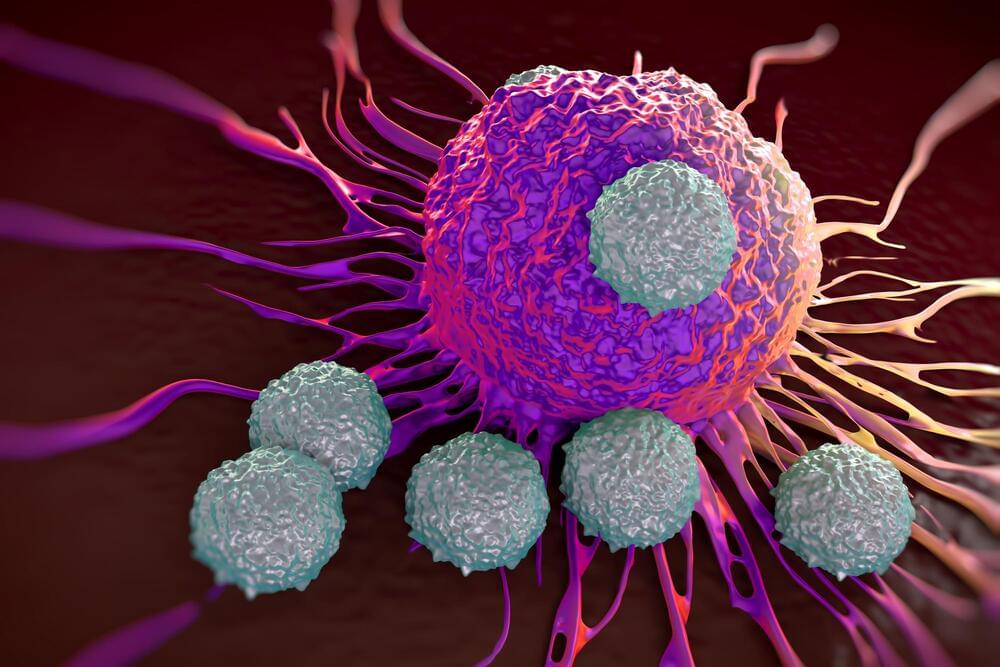
A CAR T-cell therapy targeting disease-driving immune cells safely led to sustained disease remission for five people with systemic lupus erythematosus (SLE) who’d previously failed to respond to other treatments, a recent study reported.
Treatment was also highly specific, preventing autoimmune activity, but didn’t impair general immune system function.
“These data provide new therapeutic possibilities to control SLE disease activity,” the researchers wrote. “Longer follow-ups in larger cohorts of patients will be necessary to confirm sustained absence of autoimmunity and resolution of inflammation in patients with SLE who have received CAR T cell therapy.”
Nature Abstract.
https://www.nature.com/articles/s41591-022-02017-5
No systemic lupus erythematosus patient receiving the CAR T-cell therapy infusion relapsed, all remained in remission for up to 17 months.