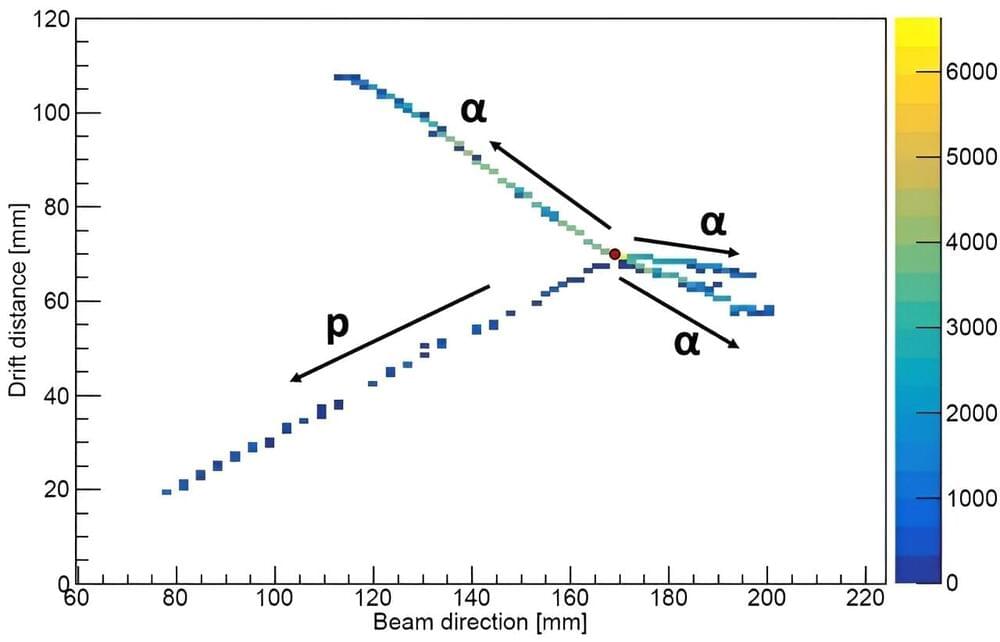
Not all of the material around us is stable. Some materials may undergo radioactive decay to form more stable isotopes. Scientists have now observed a new decay mode for the first time. In this decay, a lighter form of oxygen, oxygen-13 (with eight protons and five neutrons), decays by breaking into three helium nuclei (an atom without the surrounding electrons), a proton, and a positron (the antimatter version of an electron).
Scientists observed this decay by watching a single nucleus break apart and measuring the breakup products. The study is published in the journal Physical Review Letters.
Scientists have previously observed interesting modes of radioactive decay following the process called beta-plus decay. This is where a proton turns into a neutron and emits some of the produced energy by emitting a positron and an antineutrino. After this initial beta-decay, the resulting nucleus can have enough energy to boil off extra particles and make itself more stable.







{kind=link}