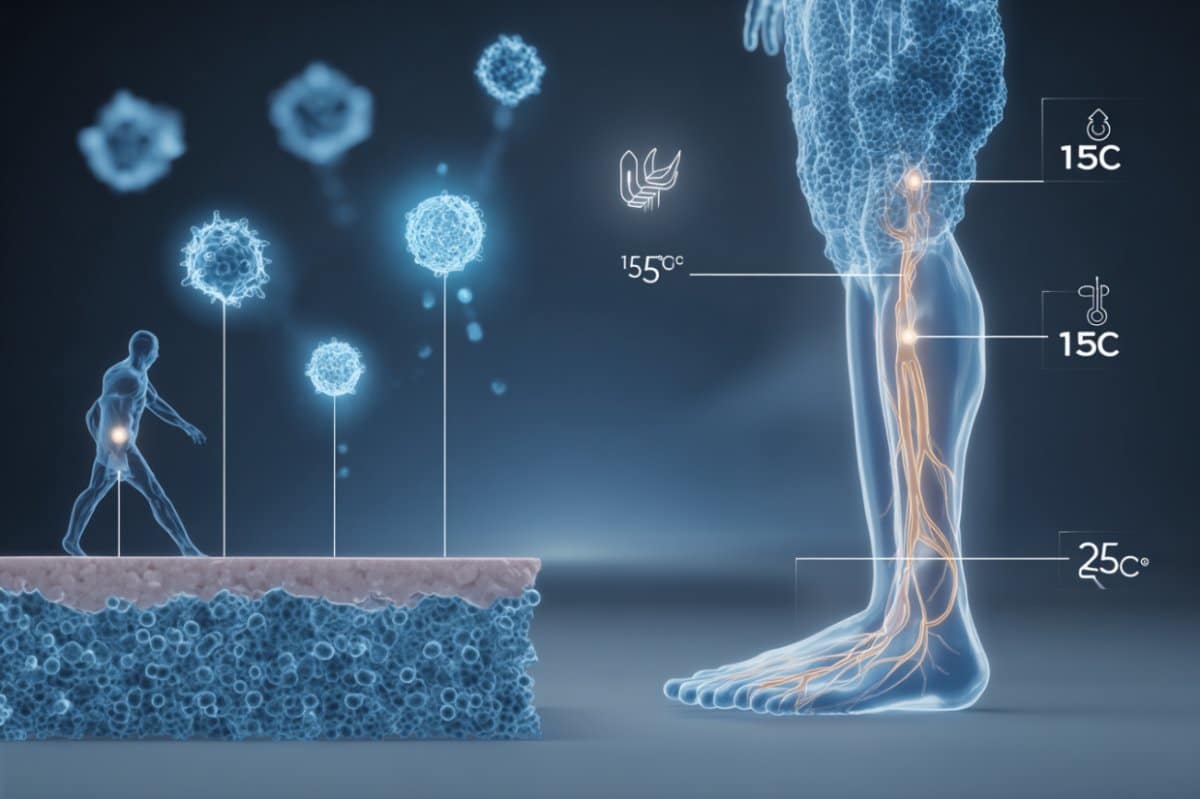
A groundbreaking study has mapped the full neural circuit that carries cool temperature signals from the skin to the brain.

For more than a century, the laws of thermodynamics have helped us understand how energy moves, how engines work, and why time seems to flow in one direction. Now, researchers have made a similarly powerful discovery, but in the strange world of quantum physics.
Scientists have shown for the first time that entanglement, the mysterious link between quantum particles, can be reversibly manipulated just like heat or energy in a perfect thermodynamic cycle.
The researchers support their findings using a novel concept called an entanglement battery, which allows entanglement to flow in and out of quantum systems without being lost, much like a regular battery stores and supplies energy.

NASA launched an incredible new web portal that reveals ground movements across North America with astonishing precision.

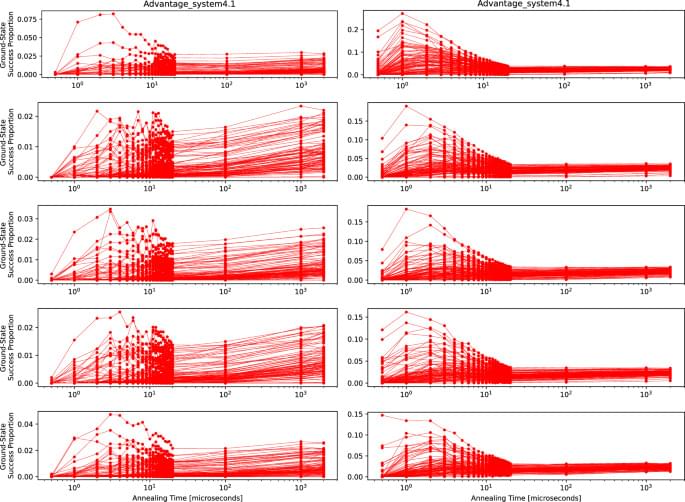
Pelofske, E., Hahn, G. & Djidjev, H.N. npj Unconv. Comput. 2, 17 (2025). https://doi.org/10.1038/s44335-025-00032-6


Amazon is hoping to get a good rhythm going with the launch and deployment of Project Kuiper, its 3,232-satellite internet constellation, which began operational flights in April. The tech giant said on Thursday that its nearly $140 million investment in Florida is a cornerstone to making that happen.
While shown in the background of photos and hinted at in other public relations materials during its first three launch campaigns, Amazon confirmed on July 24 that its payload processing facility (PPF) at the Kennedy Space Center (KSC) entered service back in April in time to support its first operational launch on a United Launch Alliance (ULA) Atlas 5 rocket.
“There is no better place than Florida’s Space Coast to fulfill Kuiper’s promise to bring broadband to unserved and underserved across the nation and world,” said Brian Huseman, Amazon’s vice president for public policy and community engagement, in a statement. “We are proud to make investments in Florida that will impact the local community and ultimately our customers. We look forward to our long-term partnership with Space Florida, NASA, Space Force, and state and local officials, as well as our launch providers and community partners.”
