We’re on a journey to advance and democratize artificial intelligence through open source and open science.

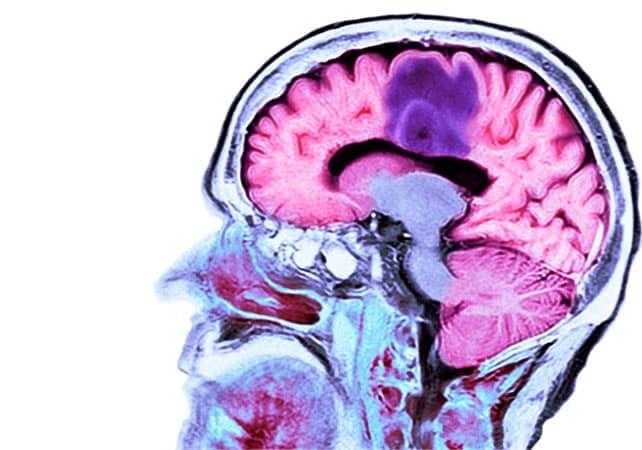
Tumor-treating fields (TTFields) are gaining traction as evidence expands beyond early enthusiasm, Medscape reports. Once considered experimental, TTFields are now supported by multiple randomized trials and are being tested across a growing list of solid tumors, positioning the therapy as a potential addition to standard cancer care in selected patients.
Here’s a look at how it works, the body of evidence, and the limitations.
Tumor treating fields use low intensity, alternating electric fields to disrupt cancer cell division.
The electric fields are generated by a wearable device — Optune Gio for glioblastoma and Optune Lua for pleural mesothelioma and NSCLC — developed and marketed by Switzerland-based oncology company Novocure.


• Ensuring ethical leadership at all levels.
Ethical considerations must be integrated into every phase of AI development—not added as an afterthought.
As AI transforms business, responsible leadership will unlock new possibilities. Responsible AI is not just about compliance—it is a strategic advantage that builds trust and drives sustainable growth in an era where technology should benefit every part of society. In domains such as supply chain management, local decisions can have global consequences. Ethical AI enables progress that stays true to shared values across all points of influence. Fair, transparent and accountable by design—this is how institutions can trust innovation to build smarter systems and a better world.

Ricardo Iriart last saw his wife conscious four years ago. Every day since, he has visited Ángeles, often spending hours talking to her in hopes that she could hear him.
Over the last year, he’s gotten a new understanding of his wife’s condition, participating in cutting-edge research into “covert consciousness.” It’s an emerging field of study that probes what patients with disorders of consciousness can comprehend, even when they can’t respond.
Earlier this year, the University of Pittsburgh became the first research institution in the U.S. to use an Austrian device called the mindBeagle in a clinical trial of covert consciousness.
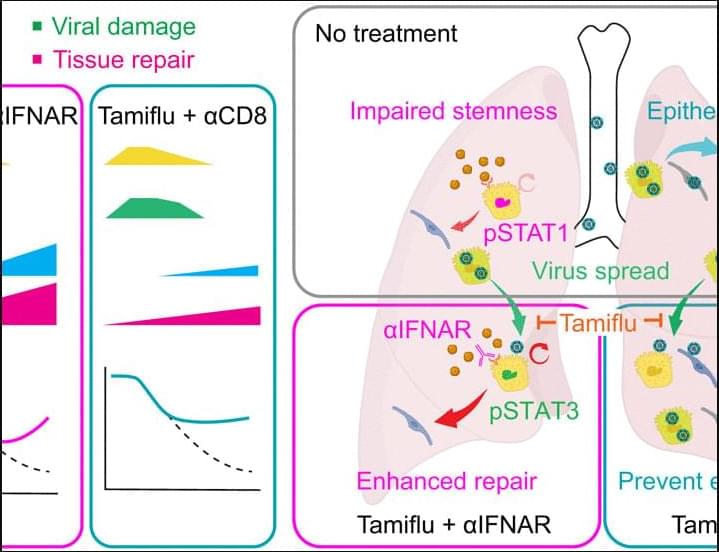
Recovery from deadly influenza infection may hinge on helping the lungs heal in addition to stopping the virus, according to a new Science study in mice.
The results show that pairing modest antiviral therapies with immune modulation can restore damaged tissues and lung function, even after severe infection has taken hold.
Maintaining tissue function while eliminating infected cells is fundamental, and inflammatory damage plays a major contribution to lethality after lung infection. We tested 50 immunomodulatory regimes to determine their ability to protect mice from lethal infection. Only neutrophil depletion soon after infection prevented death from influenza. This result suggests that the infected host passed an early tipping point after which limiting innate damage alone could not rescue lung function. We investigated treatments that could have efficacy when administered later in infection. We found that partial limitation of viral spread together with enhancement of epithelial repair, by interferon blockade or limiting CD8+ T cell–mediated killing of epithelial cells, reduced lethality.
Several types of tooth–bone attachment have evolved in different branches of amniotes. The most studied type of tooth anchorage is thecodont implantation, characterized by a nonmineralized periodontal ligament linking the tooth to the jawbone inside a deep alveolus (Bertin et al., 2018 ; Diekwisch, 2001). This attachment, called gomphosis, is present in mammals and crocodilians and provides robust resistance to mechanical stress during food processing (McIntosh et al., 2002).
By contrast, the teeth of recent lepidosaurian reptiles are firmly attached to the jaw bones, although the morphology of this type of attachment varies across species (Gaengler, 2000). In most lizards and snakes, teeth are ankylosed to the inner side of the high labial wall of the jawbone (pleurodont attachment). However, in some species (e.g., agamas, chameleons), the teeth are completely fused to the crest of the tooth-bearing bone (acrodont teeth) (Edmund, 1960). Such cases, where the teeth are firmly fused to the tooth-bearing element by mineralized tissue, are called ankylosis (for nomenclature, see a recent review by Bertin et al., 2018). Although ankylosis is widespread in nature, in mammals, a fusion of the tooth to the bone by hard tissue is considered a pathological condition (Palone et al., 2020 ; Tong et al., 2020).
Diverse developmental mechanisms have been proposed to explain the evolutionary origin and elaboration of ankylosis. The first developmental step of ankylosis is described as a soft ligament mineralization (LeBlanc et al., 2016 ; Liu et al., 2016). The periodontal ligaments in ancestral mammals have been predicted to display a high osteogenic potential, with an inclination to become calcified, thus resulting in dental ankylosis (LeBlanc et al., 2016). The mineralized ligamentous tissue has been preserved in fossilized mosasaurs, and it is also evident in several fish species and modern snakes (LeBlanc, Lamoureux, & Caldwell, 2017 ; Luan et al., 2009 ; Peyer, 1968). In the second type, ankylosis has been described as developing without ligament formation, with the tooth base firmly attached directly to the top of the tooth-bearing bony pedicles with no sign of previous ligament production (Buchtová et al., 2013 ; Luan et al., 2009).

Nuclear power company TerraPower has passed the Nuclear Regulatory Commission staff’s final safety evaluation for a permit to build a reactor in Wyoming. The Washington-based company backed by Bill Gates and NVIDIA could be the first to deploy a utility-scale, next-generation reactor in America.
TerraPower’s Natrium design pairs a small modular reactor (SMR) with an integrated thermal battery. The SMR generates 345 megawatts of continuous electrical power. The thermal battery, which stores excess heat in molten salt, allows the system to surge its output to 500 megawatts for more than five hours, generating enough energy to power 400,000 homes at maximum capacity.
“Today is a momentous occasion for TerraPower, our project partners and the Natrium design,” said company CEO Chris Levesque in a statement issued Monday. The favorable assessment “reflects years of rigorous evaluation, thoughtful collaboration with the NRC, and an unwavering commitment to both safety and innovation.”

With AI compute demands soaring, silicon photonics is emerging as a next-generation technology poised to reshape the landscape. According to Hankyung, sources say that Samsung Electronics’ Device Solutions (DS) Division has designated the technology as a future strategic priority and begun recruiting experts for its Singapore-based R&D center, led by Vice President King-Jien Chui, a former TSMC executive. The report highlights that Samsung is expanding its team in Singapore and working with Broadcom to move the technology toward commercialization.
As the report indicates, citing industry sources, Samsung’s 2027 target for CPO (Co-Packaged Optics) commercialization suggests that its real contest with TSMC will begin at that point. By 2030—when silicon photonics is expected to be applied at the individual-chip level—the technology will likely become the central battleground of the foundry market. Although TSMC currently leads, Samsung is gearing up, viewing the technology as a key to attracting major foundry clients, the report adds.