The AIs are “getting better at pretending to be knowledgeable.”
As AI chatbots get bigger and more powerful, they are also lying more, instead of declining questions they can’t answer.


Summary: Researchers found that mutations in the Sox3 gene cause hypopituitarism, a condition where the pituitary gland produces insufficient hormones, leading to growth issues and infertility. In a study on mice, they discovered that Sox3 mutations affect brain cells called NG2 glia, which are essential for hormone production.
Treating the mice with aspirin or altering their gut microbiome restored NG2 glia levels and reversed hypopituitarism. These findings suggest that both aspirin and gut bacteria could be explored as potential treatments for people with Sox3 mutations or other hormone-related disorders.
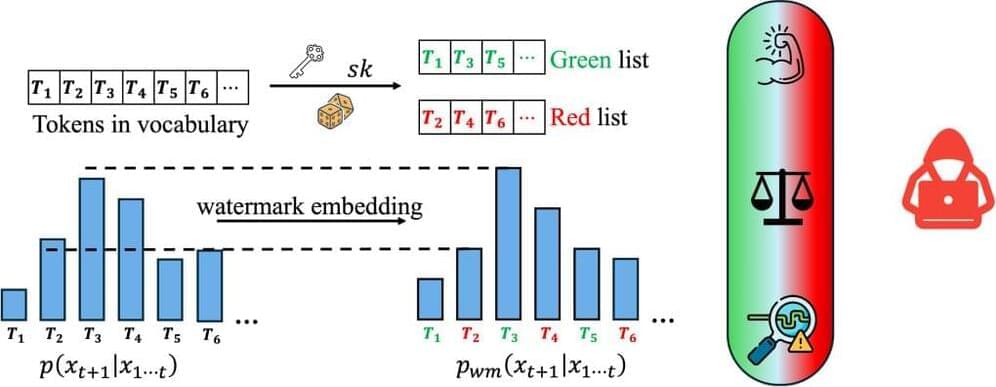
The researchers examine the effectiveness of watermarking in large language models (LLMs) and find that current methods, while promising, have serious weaknesses.
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that embeds information in the output of a model to verify its source, aims to mitigate the misuse of such AI-generated content. Current state-of-the-art watermarking schemes embed watermarks by slightly perturbing probabilities of the LLM’s output tokens, which can be detected via statistical testing during verification.
Unfortunately, our work shows that common design choices in LLM watermarking schemes make the resulting systems surprisingly susceptible to watermark removal or spoofing attacks—leading to fundamental trade-offs in robustness, utility, and usability. To navigate these trade-offs, we rigorously study a set of simple yet effective attacks on common watermarking systems and propose guidelines and defenses for LLM watermarking in practice.
Similar to image watermarks, LLM watermarking embeds invisible secret patterns into the text. Here, we briefly introduce LLMs and LLM watermarks. We use \(x\) to denote a sequence of tokens, \(x_i \in \mathcal{V}\) represents the \(i\)-th token in the sequence, and \(\mathcal{V}\) is the vocabulary. \(M_{\text{orig}}\) denotes the original model without a watermark, \(M_{\text{wm}}\) is the watermarked model, and \(sk \in \mathcal{S}\) is the watermark secret key sampled from \(\mathcal{S}\).
The Linac Coherent Light Source (LCLS), the world’s most powerful X-ray laser located at the SLAC National Accelerator Laboratory in the US, is set for a major upgrade that will increase its X-ray energy 3,000-fold, a press release shared with Interesting Engineering said.
When complete, the upgrade will let scientists explore atomic-scale processes in their search for answers in biology, materials science, quantum physics, and much more.

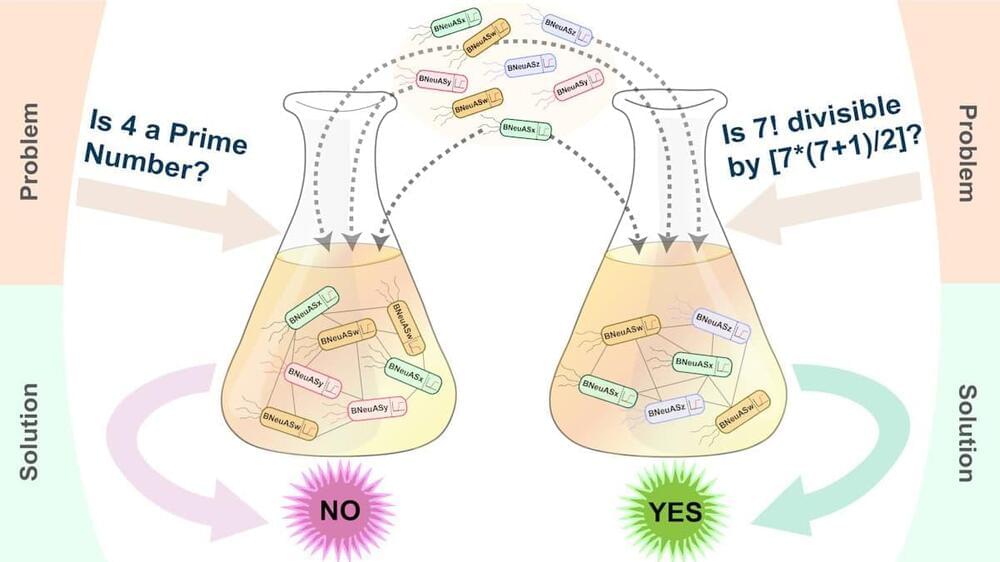
Researchers have developed a groundbreaking system that uses bacteria to mimic the problem-solving capabilities of artificial neural networks.
Cell-based biocomputing is a novel technique that uses cellular processes to perform computations. Such micron-scale biocomputers could overcome many of the energy, cost and technological limitations of conventional microprocessor-based computers, but the technology is still very much in its infancy. One of the key challenges is the creation of cell-based systems that can solve complex computational problems.
Now a research team from the Saha Institute of Nuclear Physics in India has used genetically modified bacteria to create a cell-based biocomputer with problem-solving capabilities. The researchers created 14 engineered bacterial cells, each of which functioned as a modular and configurable system. They demonstrated that by mixing and matching appropriate modules, the resulting multicellular system could solve nine yes/no computational decision problems and one optimization problem.
The cellular system, described in Nature Chemical Biology, can identify prime numbers, check whether a given letter is a vowel, and even determine the maximum number of pizza or pie slices obtained from a specific number of straight cuts. Here, senior author Sangram Bagh explains the study’s aims and findings.
In 2012, 7-year-old Emily Whitehead became the first pediatric patient to receive pioneering chimeric antigen receptor (CAR-T) therapy to fight the recurrence of acute lymphoblastic leukemia (ALL). Twelve years later, Emily is in remission and a student at the University of Pennsylvania, where the therapy was developed. But for many others, the fight continues: more than half of ALL patients experience a relapse within one year following CAR-T therapy.

In the popular tv show big bang theory kaon decay was discovered at cern that won sheldon cooper and Amy the Nobel prize in super asymmetry and this elusive particle has been discovered. What a remarkable discovery face_with_colon_three
Researchers at CERN have observed an exceptionally rare particle decay event, potentially paving the way to uncover new physics beyond the current understanding of fundamental particles and their interactions.
This decay is extraordinarily uncommon—according to the Standard Model ℠ of particle physics, which describes particle interactions, fewer than one in every 10 billion kaons undergo this specific decay.
The NA62 experiment was developed and optimized precisely to detect and study this elusive kaon decay process.
{kind=link}