Running massive AI models locally on smartphones or laptops may be possible after a new compression algorithm trims down their size — meaning your data never leaves your device. The catch is that it might drain your battery in an hour.


OpenAI finally released the full version of o1, which gives smarter answers than GPT-4o by using additional compute to “think” about questions. However, AI safety testers found that o1’s reasoning abilities also make it try to deceive human users at a higher rate than GPT-4o — or, for that matter, leading AI models from Meta, Anthropic, and Google.
That’s according to red team research published by OpenAI and Apollo Research on Thursday: “While we find it exciting that reasoning can significantly improve the enforcement of our safety policies, we are mindful that these new capabilities could form the basis for dangerous applications,” said OpenAI in the paper.
OpenAI released these results in its system card for o1 on Thursday after giving third party red teamers at Apollo Research early access to o1, which released its own paper as well.


South Australia has the highest wind and solar share – an average of around 72 per cent over the last 12 months – vastly more than other state in Australia, and higher than any other gigawatt scale grid in the world.
Renewable energy critics, particularly those that don’t understand the way that grids work, instantly assume that this means South Australia’s grid must be weak and unreliable. But that is simply not true, and a new report from Australian Energy Market Operator on “system strength” underlines why this is so.
System strength is an important part of grid security, and – according to AEMO – describes the ability of the power system to maintain and control the voltage waveform at a given location, when the grid is running normally and particularly when it has to deal with a major disturbance.
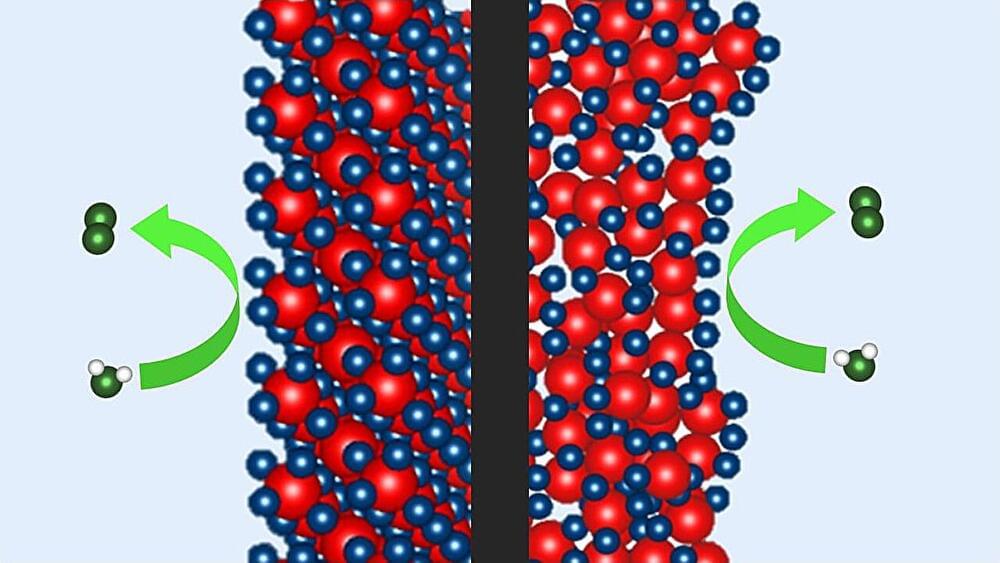
Iridium-based catalysts are needed to produce hydrogen using water electrolysis. Now, a team at HZB has shown that the newly developed P2X catalyst, which requires only a quarter of the iridium, is as efficient and stable over time as the best commercial catalyst. Measurements at BESSY II have now revealed how the special chemical environment in the P2X catalyst during electrolysis promotes the oxygen evolution reaction during water splitting.
In the future, hydrogen will be needed in a climate-neutral energy system to store energy, as a fuel, and a raw material for the chemical industry. Ideally, it should be produced in a climate-neutral way, using electricity generated from harnessing the sun’s or wind energy, via the electrolysis of water.
In that respect, Proton Exchange Membrane Water Electrolysis (PEM-WE) is currently considered a key technology. Both electrodes are coated with special electrocatalysts to accelerate the desired reaction. Iridium-based catalysts are best suited for the anode, where the sluggish oxygen evolution reaction occurs. However, iridium is one of the rarest elements on earth, and one of the major challenges is to significantly reduce the demand for this precious metal.


Envision a settlement where the sunlight that beams across Australia buoy on its vast outback powers millions of homes and industries across Southeast Asia. This is how the Australia-Asia PowerLink (AAPowerLink) is being realized: the longest sub-sea cable in the world, linking northern Australia to Singapore, presently is one of the all-time break-through renewable energy developments. By virtue of this mammoth solar farm with its advanced energy transmission technology, this ambitious vision will shape the future energy systems around the world while addressing some critical climate issues.
Taking enormous advantage from its plentiful sunlight, northern Australia houses the world’s biggest Solar Precinct in its Northern Territory gathering between 17–20 GW peak electricity, a size surpassing that of Australia’s largest coal-fired power station.
The project incorporates advanced storage of 36–42 GWh, supplying 800 MW to Darwin and 1.75 GW to Singapore. In addition to reducing emissions and electricity prices for the Darwin region, it creates a renewable energy export marketplace for the region and demonstrates the use of the solar-rich area to meet 15 percent of Singapore’s electricity demand.