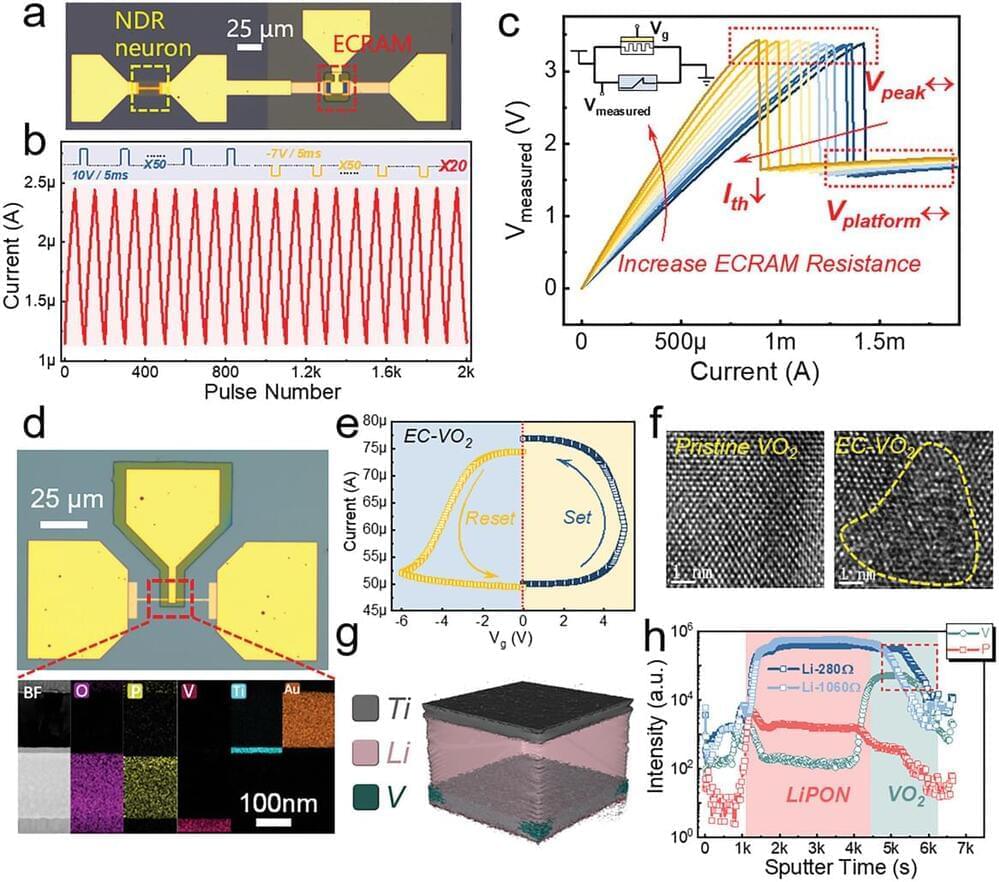
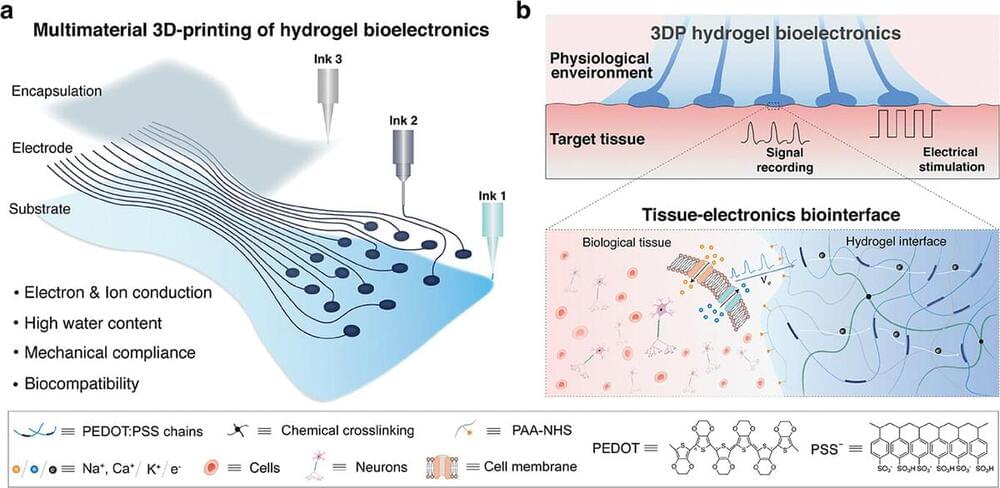
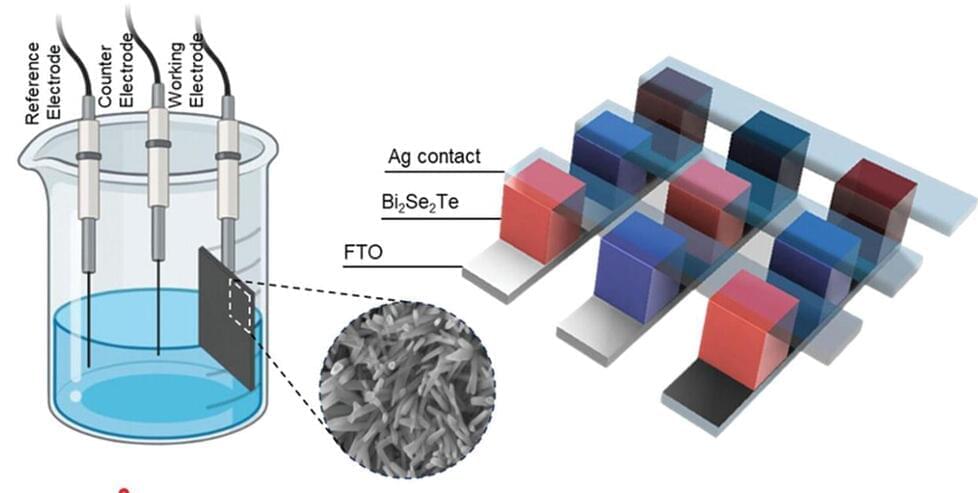
Researchers create fully memristive neuromorphic chip integrating trainable dendritic neurons and high-density RRAM, enabling energy-efficient brain-inspired computing architectures.
Many of today’s quantum devices rely on collections of qubits, also called spins. These quantum bits have only two energy levels, the ‘0’ and the ‘1’. However, unlike classical bits, qubits can exist in superpositions, meaning they can simultaneously be in a combination of the ‘0’ and ‘1’ states. Spins in real devices also interact with light and vibrations known as bosons, greatly complicating calculations.
In a new publication in Physical Review Letters (“Fast quantum state preparation and bath dynamics using non-Gaussian variational Ansatz and quantum optimal control”), researchers in Amsterdam demonstrate a way to describe spin-boson systems and use this to efficiently configure quantum devices in a desired state.
Quantum devices use the quirky behaviour of quantum particles to perform tasks that go beyond what ‘classical’ machines can do, including quantum computing, simulation, quantum sensing, quantum communication and quantum metrology. These devices can take many forms, such as a collection of superconducting circuits, or a lattice of atoms or ions held in place by lasers or electric fields.

Researchers at Rensselaer Polytechnic Institute have fabricated a device no wider than a human hair that will help physicists investigate the fundamental nature of matter and light. Their findings, published in the journal Nature Nanotechnology (“Topological valley Hall polariton condensation”), could also support the development of more efficient lasers, which are used in fields ranging from medicine to manufacturing.
The device is made of a special kind of material called a photonic topological insulator. A photonic topological insulator can guide photons, the wave-like particles that make up light, to interfaces specifically designed within the material while also preventing these particles from scattering through the material itself.
Because of this property, topological insulators can make many photons coherently act like one photon. The devices can also be used as topological “quantum simulators,” miniature laboratories where researchers can study quantum phenomenon, the physical laws that govern matter at very small scales.
Alex Rosenberg is the R. Taylor Cole Professor of Philosophy at Duke University. His research focuses on the philosophy of biology and science more generally, mind, and economics.
/ friction.
/ discord.
/ frictionphilo.
00:00 — Introduction.
01:47 — Scientism.
05:16 — Naturalism.
08:08 — Methodological or substantive?
09:40 — Eliminativism about intentionality.
11:50 — Moorean shift.
13:28 — Arguments against eliminativism.
21:19 — Papineau on intentionality.
25:43 — Consciousness.
29:29 — Companions in guilt.
31:30 — Fodor and natural selection.
37:26 — No selection for?
38:16 — Properties.
39:21 — Selection for/against.
40:34 — Selection for long necks in giraffes.
42:26 — Speaking with the vulgar?
44:26 — Selection against as intensional.
47:12 — Function and selection for.
49:11 — Skepticism.
50:59 — Example.
52:06 — Mereological nihilism.
53:23 — Value of philosophy.
55:22 — Nihilism?
1:00:03 — Conclusion.
Music: PaulFromPayroll — High Rise


Summary: Researchers developed a drone that flies autonomously using neuromorphic image processing, mimicking animal brains. This method significantly improves data processing speed and energy efficiency compared to traditional GPUs.
The study highlights the potential for tiny, agile drones for various applications. The neuromorphic approach allows the drone to process data up to 64 times faster while consuming three times less energy.
{kind=link}
{kind=link}