With a full mouse connectome on the horizon, neuroscience needs to overcome its legacy of minimalism and embrace the contemporary challenge of representing whole-nervous-system connectivity.


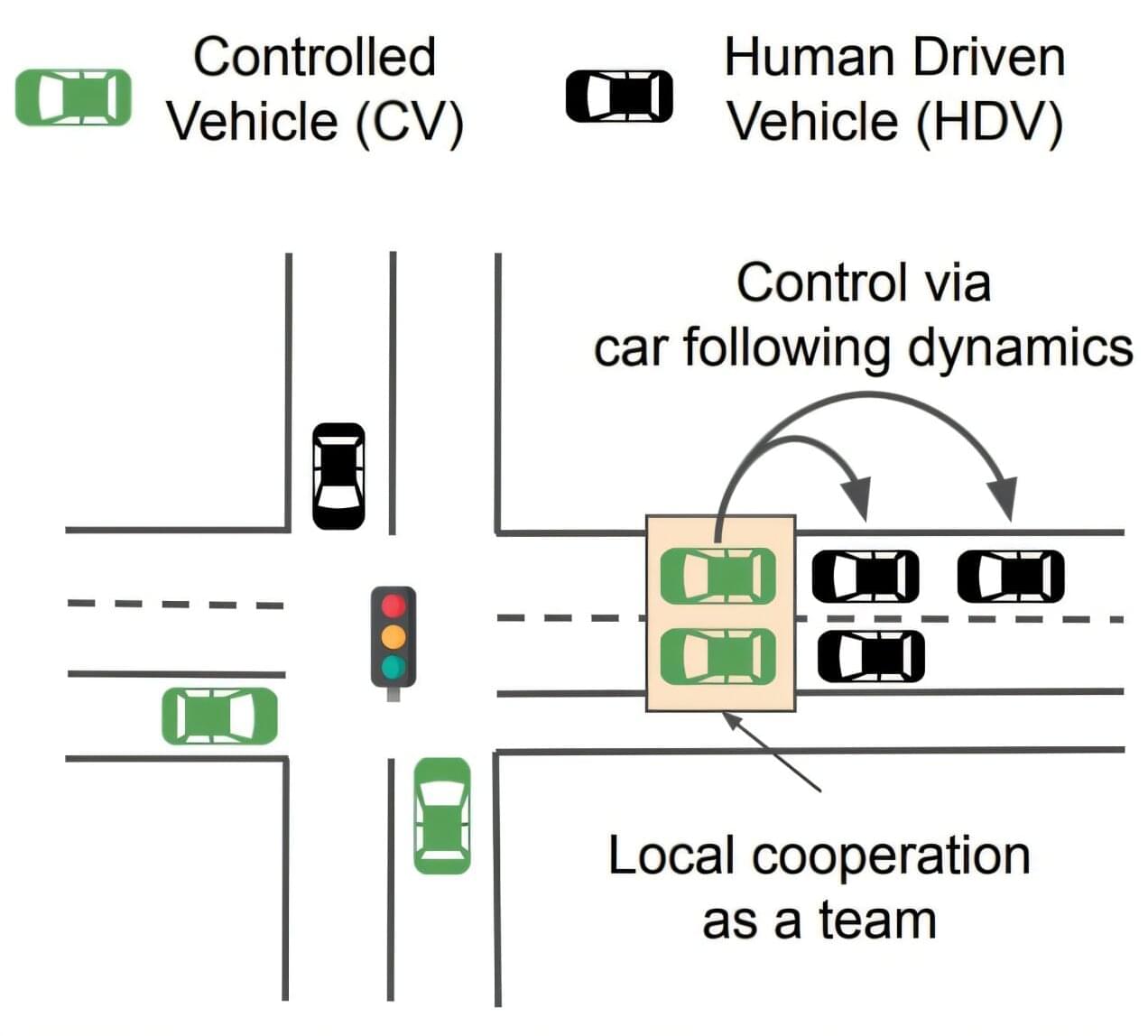
If there’s one thing that characterizes driving in any major city, it’s the constant stop-and-go as traffic lights change and as cars and trucks merge and separate and turn and park. This constant stopping and starting is extremely inefficient, driving up the amount of pollution, including greenhouse gases, that gets emitted per mile of driving.
One approach to counter this is known as eco-driving, which can be installed as a control system in autonomous vehicles to improve their efficiency.
How much of a difference could that make? Would the impact of such systems in reducing emissions be worth the investment in the technology? Addressing such questions is one of a broad category of optimization problems that have been difficult for researchers to address, and it has been difficult to test the solutions they come up with. These are problems that involve many different agents, such as the many different kinds of vehicles in a city, and different factors that influence their emissions, including speed, weather, road conditions, and traffic light timing.

Humans’ relationships with plants is largely utilitarian, serving our needs. We generally either eat them or make things out of them.
Researchers in the College of Human Ecology (CHE) have developed a design and fabrication approach that treats these living things as companions to humans, with seeds woven into hydrogel material for hairbands, wristbands, hats and sandals, among other applications. The seeds grow into sprouts if taken care of properly.
“For most of human history, we have lived alongside plants, and they’ve been leveraged by humans to be used as food or spun into yarns for fabric,” said Cindy Hsin-Liu Kao, associate professor of human centered design (CHE).

In the dim light of the lab, friends, family, and strangers watched the image of a pianist playing for them, the pianist’s fingers projected onto the moving keys of a real grand piano that filled the space with music.
Watching the ghostly musicians, faces and bodies blurred at their edges, several listeners shared one strong but strange conviction: “feeling someone’s presence” while “also knowing that I am the only one in the room.”
“It’s tough to explain,” another listener said. “It felt like they were in the room with me, but at the same time, not.”
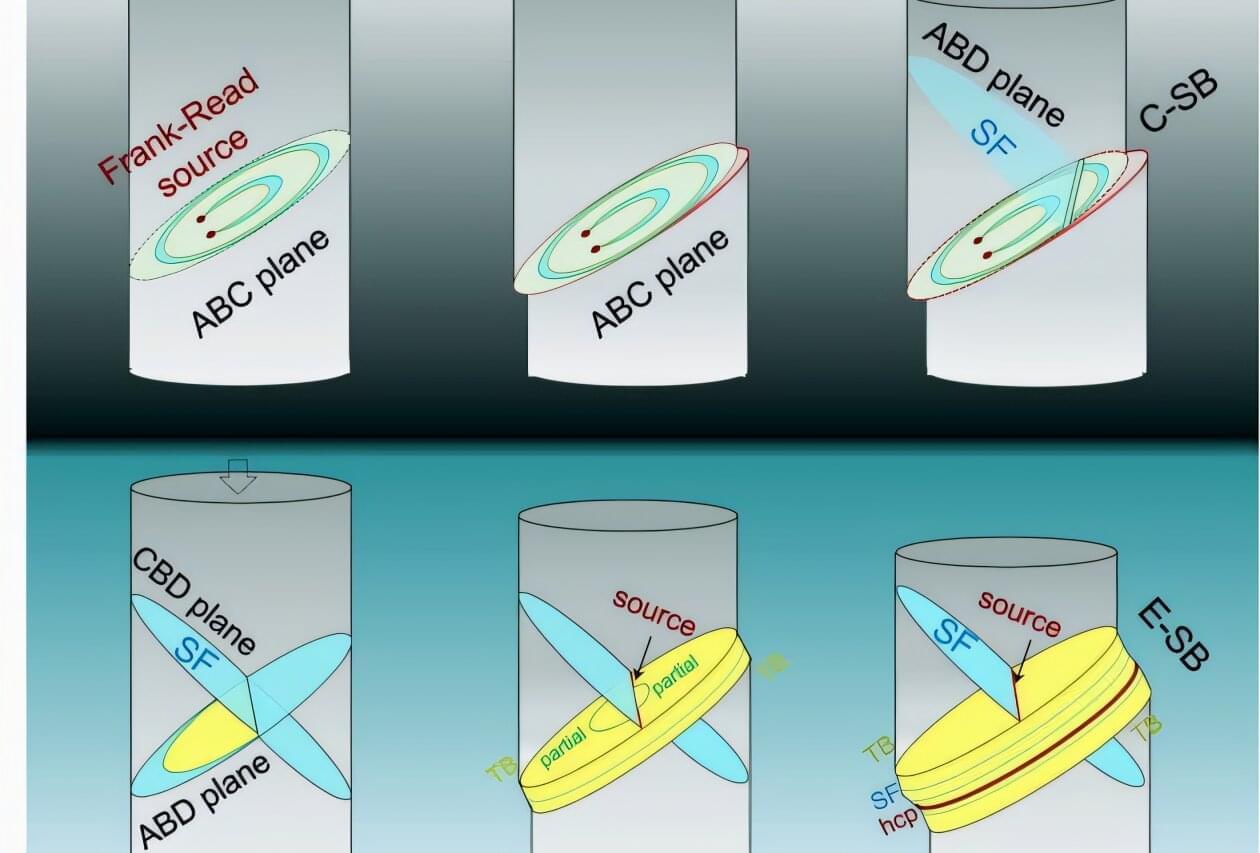
University of California, Irvine scientists have expanded on a longstanding model governing the mechanics behind slip banding, a process that produces strain marks in metals under compression, gaining a new understanding of the behavior of advanced materials critical to energy systems, space exploration and nuclear applications.
In a paper published recently in Nature Communications, researchers in UC Irvine’s Samueli School of Engineering report the discovery of extended slip bands—a finding that challenges the classic model developed in the 1950s by physicists Charles Frank and Thornton Read.
While the Frank–Read theory attributes slip band formation to continuous dislocation multiplication at active sources, the UC Irvine team found that extended slip bands emerge from source deactivation followed by the dynamic activation of new dislocation sources.

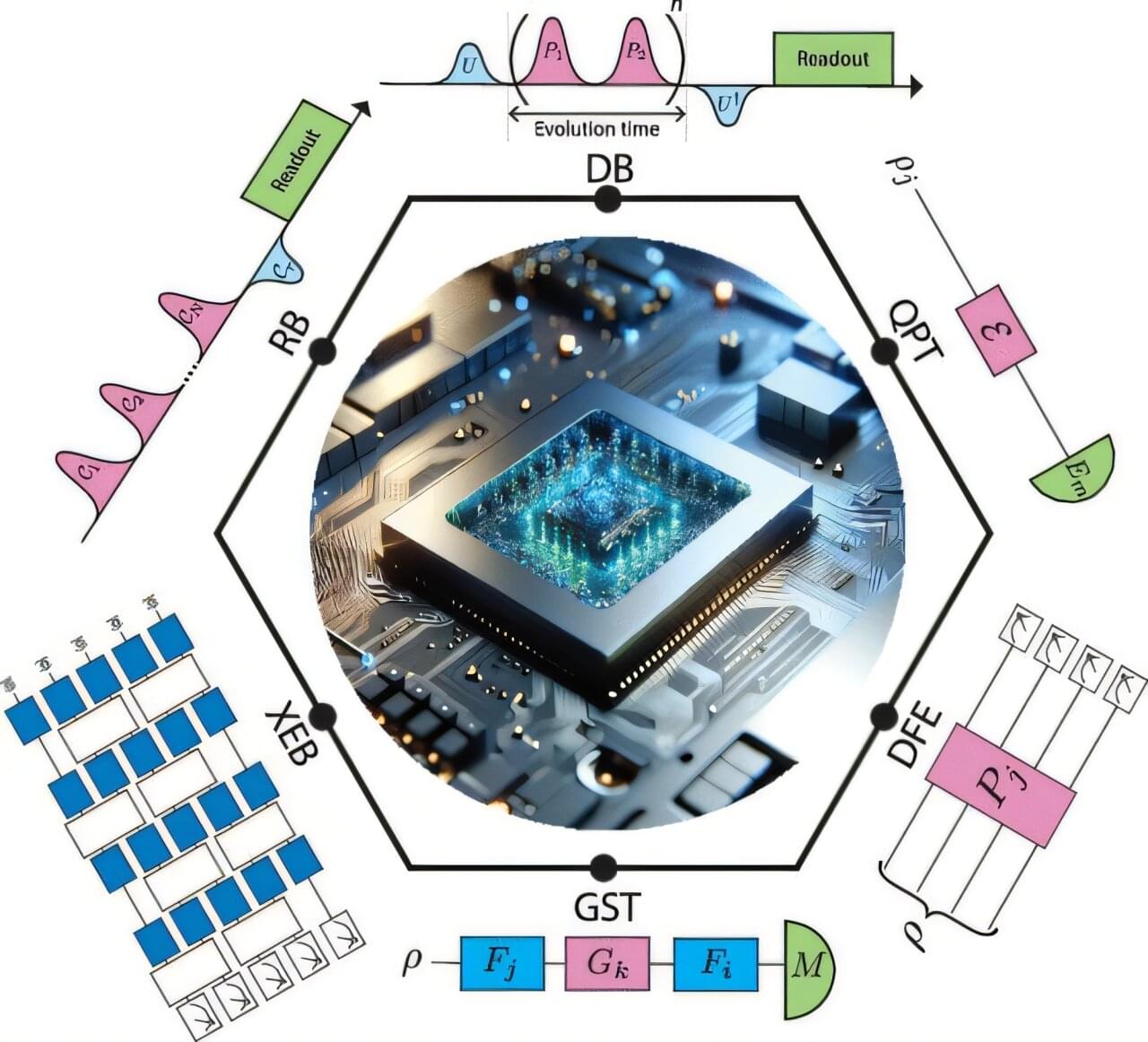
Researchers have developed a new protocol for benchmarking quantum gates, a critical step toward realizing the full potential of quantum computing and potentially accelerating progress toward fault-tolerant quantum computers.
The new protocol, called deterministic benchmarking (DB), provides a more detailed and efficient method for identifying specific types of quantum noise and errors compared to widely used existing techniques.
The work is published in the journal Chemical Reviews.
{kind=link}