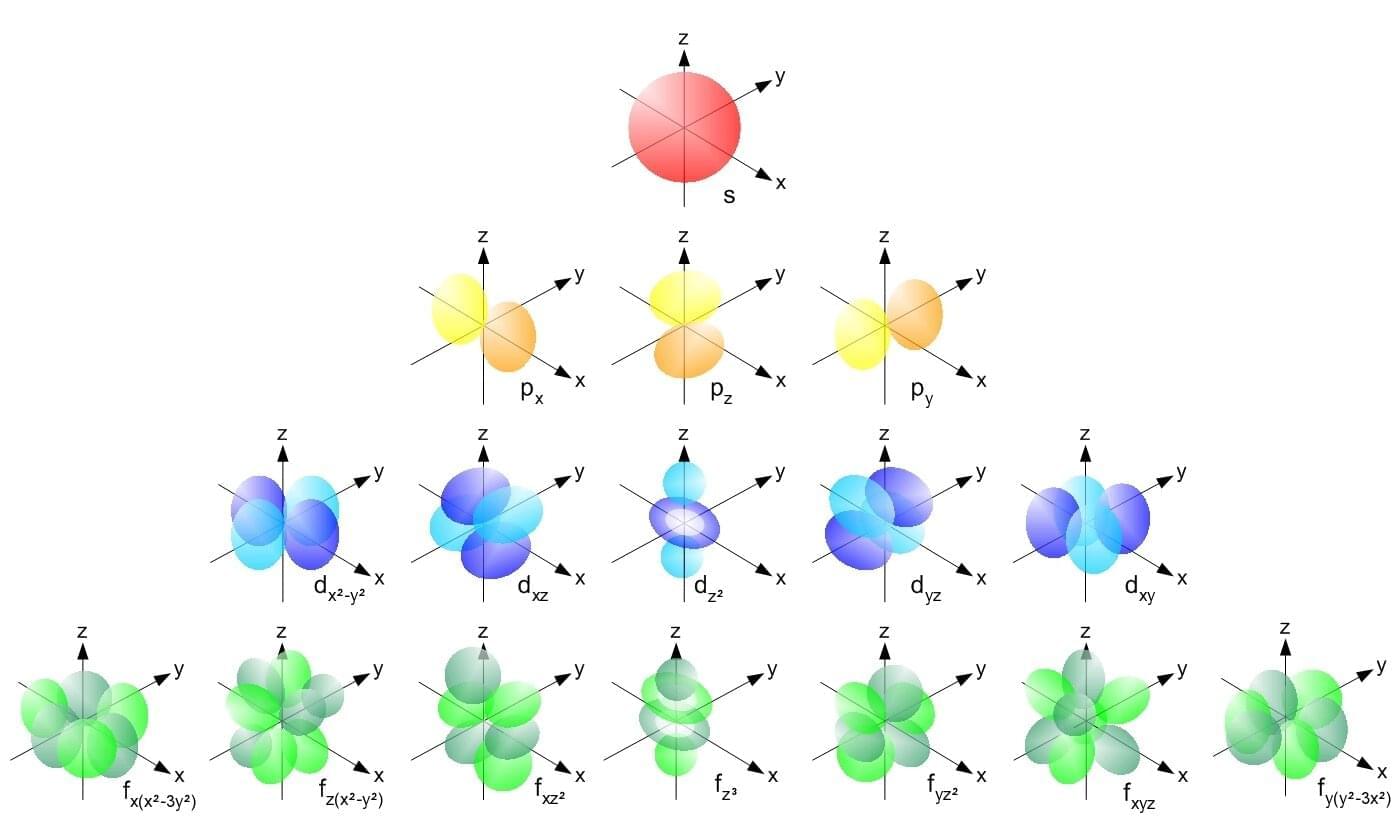
PRESS RELEASE — Quantum computers promise to speed calculations dramatically in some key areas such as computational chemistry and high-speed networking. But they’re so different from today’s computers that scientists need to figure out the best ways to feed them information to take full advantage. The data must be packed in new ways, customized for quantum treatment.
Researchers at the Department of Energy’s Pacific Northwest National Laboratory have done just that, developing an algorithm specially designed to prepare data for a quantum system. The code, published recently on GitHub after being presented at the IEEE International Symposium on Parallel and Distributed Processing, cuts a key aspect of quantum prep work by 85 percent.
While the team demonstrated the technique previously, the latest research addresses a critical bottleneck related to scaling and shows that the approach is effective even on problems 50 times larger than possible with existing tools.