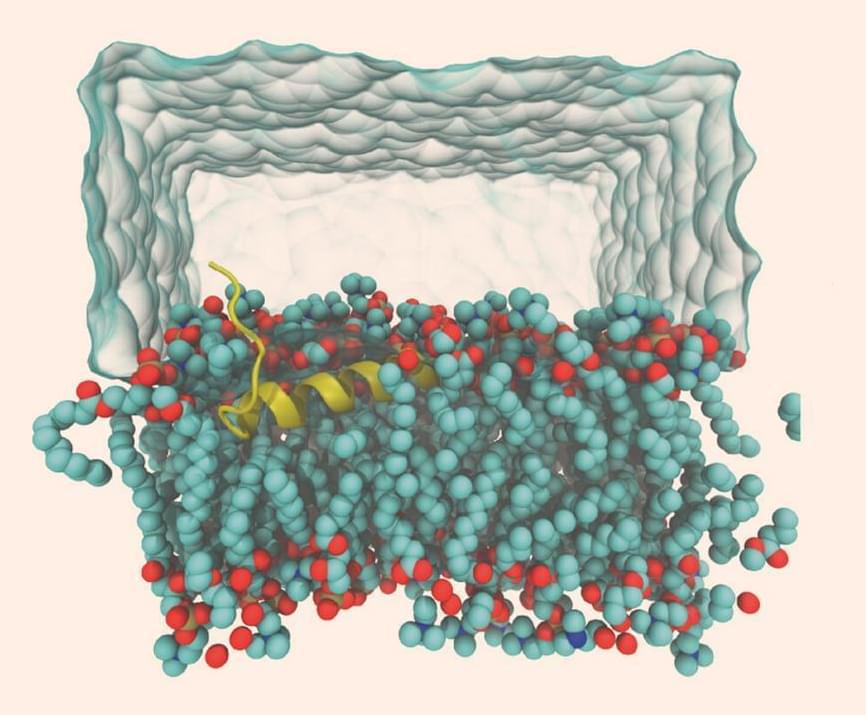
Learn the basics of neural networks and backpropagation, one of the most important algorithms for the modern world.
Category: robotics/AI – Page 538

If we want artificial “superintelligence,” it may need to feel pain
“It might be that to get superhuman intelligence, you do need some level of sentience. We can’t rule that out either; it’s entirely possible. Some people argue that that kind of real intelligence requires sentience and that sentience requires embodiment. Now, there is a view in philosophy, called computational functionalism, that [argues] sentience, sapience, and selfhood could just be the computations they perform rather than the body they’re situated in. And if that view is correct, then it’s entirely possible that by recreating the computations the brain performs in AI systems, we also thereby recreate the sentience as well.”
Birch is saying three things here. First, it’s reasonable to suggest that “superintelligence” requires sentience. Second, we could potentially recreate sentience in AI with certain computations. Therefore, if we want AI to reach “superintelligence” we would need it to be sentient. We would need AI to feel things. ChatGPT needs to know pain. Gemini needs to experience euphoria.
The fact that underlies Birch’s book and our conversation is that intelligence is not some deus ex machina dropped from the sky. It is not some curious alien artifact uncovered in a long, lost tomb. It’s nested within an unfathomably long evolutionary chain. It’s the latest word in a long sentence. But the question Birch raises is: Where does AI fit in the book of evolved intelligence?


Why AI Is A Philosophical Rupture
Be that as it may, there is nothing much symbolic here. At least not in the classical sense of the term.
I am emphasizing this absence of the symbolic because it is a beautiful way to show that deep learning has led to a pretty powerful philosophical rupture: Implicit in the new concept of intelligence is a radically different ontological understanding of what it is to be human, indeed, of what reality is or of how it is structured and organized.
Understanding this rupture with the older concept of intelligence and ontology of the human/the world is key, I think, to understanding your actual question: Are we entering what you call a new AIxial age, where AI will amount to something similar to what writing amounted to roughly 3,000 to 2,000 years ago?

Direct Solar Power Prediction from Machine Learning
How can machine learning help determine the best times and ways to use solar energy? This is what a recent study published in Advances in Atmospheric Sciences hopes to address as a team of researchers from the Karlsruhe Institute of Technology investigated how machine learning algorithms can be used to predict and forecast weather patterns to enable more cost-effective approaches for using solar energy. This study has the potential to help enhance renewable energy technologies by fixing errors that are often found in current weather prediction models, leading to more efficient use of solar power by predicting when weather patterns will enable the availability of the Sun for solar energy needs.
For the study, the researchers used a combination of statistical methods and machine learning algorithms to help predict the most efficient times of day that photovoltaic (PV) power generation will achieve maximum production output. Their methods used what’s known as post-processing, which involves correcting weather forecasting errors before that data enters PV models, resulting in changing PV model predictions, resulting in establishing more accurate weather forecasting from machine learning algorithms.
“One of our biggest takeaways was just how important the time of day is,” said Dr. Sebastian Lerch, who is a professor at the Karlsruhe Institute of Technology and a co-author on the study. “We saw major improvements when we trained separate models for each hour of the day or fed time directly into the algorithms.”
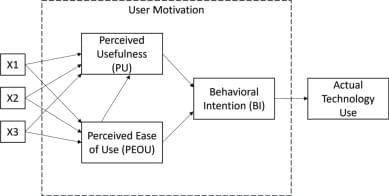
Addressing the use of generative AI in academic writing
The rise of generative AI has been a major disruptive force in academia. Academics are concerned about its impact on student learning. Students can use generative AI technologies, such as ChatGPT, to complete many academic tasks on their behalf. This could lead to poor academic outcomes as students use ChatGPT to complete assessments, rather than engaging with the learning material. One particularly vulnerable academic activity is academic writing. This paper reports the results of an active learning intervention where ChatGPT was used by students to write an academic paper. The resultant papers were then analysed and critiqued by students to highlight the weaknesses of such AI-produced papers. The research used the Technology Acceptance Model to measure changing student perceptions about the usefulness and ease of use of ChatGPT in the creation of academic text.

The NanoBots Are Coming, How Will They Affect Us In The Future?
Go to https://historicmail.com/DROID and check out with code DROID to get 10% off on their Christmas Sale on your gifts and help support the channel. Thanks to Historic Mail for sponsoring this video!
Machines so tiny they would be far smaller than a human blood cell, this is the promise of nanotechnology, and they already exist but how are they even made and will they be scarier than A.I. Experts say that we are just at the beginning of the nanobot revolution and what they promise could little short of miraculous. In this video we look at how we got here and what the current state of the art is.
To give one off tips and donations please use the following :
https://www.buymeacoffee.com/curiousdroid.
Patreon : https://www.patreon.com/curiousdroid — For longer term channel support.
Paypal.me : https://paypal.me/curiousdroid — For 1 off direct tips and thank you payments.
Facebook : https://www.facebook.com/curiousdroid.
Quote: “We are like butterflies who flutter for a day and think it’s forever” : Carl Sagan.