BMW halts the production of internal combustion engines, in its own country at least. Now its main German plant will produce EVs only.

Spacedock delves into animalistic bioship designs from across science fiction.
THE SOJOURN — AN ORIGINAL SCI-FI AUDIO DRAMA:
https://www.thesojournaudiodrama.com/
BECOME A CHANNEL MEMBER:
https://www.youtube.com/channel/UCfjaAUlTZRHJapJmCT6eyIg/join.
SUPPORT SPACEDOCK:
https://www.patreon.com/officialspacedock?ty=h.
MERCHANDISE:
https://teespring.com/en-GB/stores/spacedock-2
Do not contact regarding network proposals.





Tesla has signed a deal with the EG Group, a massive gas station and convenience store operator, to sell its Supercharger hardware to be deployed as an EG-branded product.
It’s the second of such deals that Tesla has made in just a few weeks.
Last month, Tesla surprised many when it announced it reached a deal with BP to sell them $100 million worth of Supercharger hardware to be deployed at BP gas stations across the US under the BP brand.
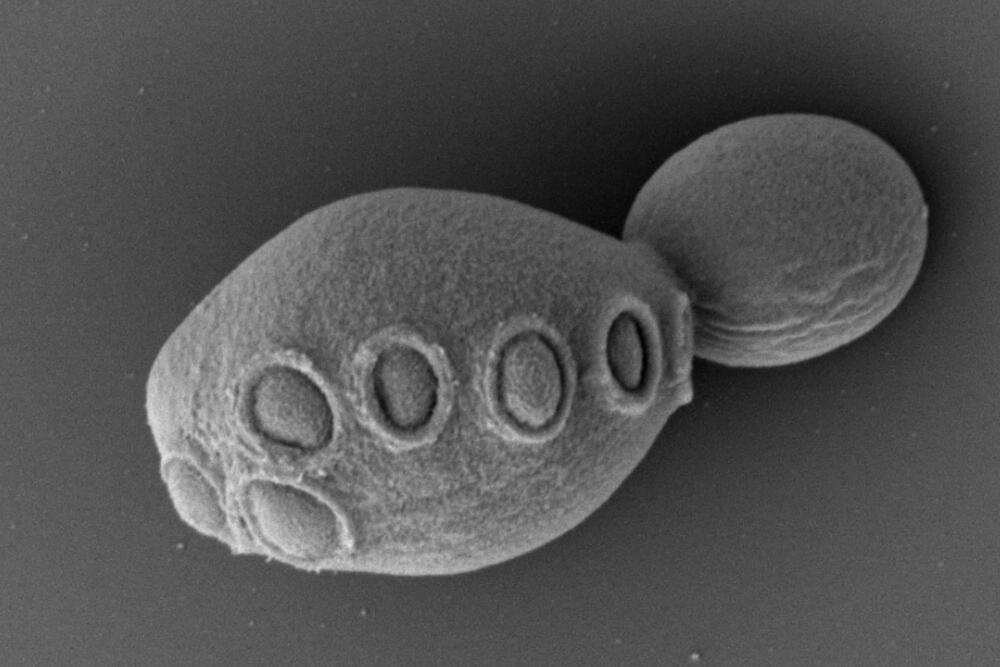
In a milestone achievement, a whole chromosome has been created from scratch by scientists for the first time ever.
The tRNA Neochromosome is a man-made chromosome of the common baker’s yeast Saccharomyces cerevisiae. It may soon allow for the creation of synthetic and superior yeast cells, according to a collection of new papers in the scientific journals Cell and Cell Genomics.
This discovery is the newest in an international project called Sc2.0, which has also synthesized all 16 of the yeast’s chromosomes with an aim to combine them into a functional cell that might help make yeast faster, more resilient and more productive.

On Monday, Nvidia announced the HGX H200 Tensor Core GPU, which utilizes the Hopper architecture to accelerate AI applications. It’s a follow-up of the H100 GPU, released last year and previously Nvidia’s most powerful AI GPU chip. If widely deployed, it could lead to far more powerful AI models—and faster response times for existing ones like ChatGPT—in the near future.
According to experts, lack of computing power (often called “compute”) has been a major bottleneck of AI progress this past year, hindering deployments of existing AI models and slowing the development of new ones. Shortages of powerful GPUs that accelerate AI models are largely to blame. One way to alleviate the compute bottleneck is to make more chips, but you can also make AI chips more powerful. That second approach may make the H200 an attractive product for cloud providers.
The Earth spins at different rates depending where you are on the globe. If it started to spin faster, you’d eventually be too dead to worry about it.
{kind=link}